научный
журнал
Срочная публикация научной статьи
+7 995 770 98 40
+7 995 202 54 42
info@journalpro.ru

USING R LANGUAGE BSTS PACKAGE FOR MODELLING BAYESIAN STRUCTURAL TIME SERIES

Рубрика: Технические науки
Журнал: «Евразийский Научный Журнал №5 2023» (май, 2023)
Количество просмотров статьи: 1727
Показать PDF версию USING R LANGUAGE BSTS PACKAGE FOR MODELLING BAYESIAN STRUCTURAL TIME SERIES
Zhu Zhongwen,
Sherstneva S.V.
Tomsk Polytechnic University, Russia, Tomsk
Introduction
Forecasting is an important tool in various fields, in particular economics, finance, meteorology, climatology, data science and other subject areas. Prediction refers to the process of estimating future values or states of a system based on available data and knowledge of past values and trends. Predictive analysis allows for more informed decision-making based on probabilistic estimates of future system development, which can be useful for planning, resource management and strategic decision-making.
Currently, time series are one of the most common objects of analysis. This necessitates the development of effective methods for estimating time series parameters, which will provide better predictions of measured parameters and identify patterns in their changes. There are many models for analyzing and forecasting time series. One promising approach in time series analysis is to represent it as a Bayesian structural time series (BSTS model)
BSTS model
In Bayesian structural models, the time series is represented as a sum of unobservable components, which can be interpreted, for example, as trend, seasonality, cycle, error. The Bayesian approach to statistical problems is fundamentally probabilistic. A joint probability distribution is used to describe the relationships between all the unknowns and the data. The inference is then based on a conditional probability distribution of the unknowns given the observed data — an a posteriori distribution. Using the internal consistency of the probability system, the posterior distribution extracts relevant information from the data and provides a complete and consistent representation of all state variables (including unobserved components) to discover causal relationships between the prediction and observed data. The use of the posterior distribution to solve specific inference and decision-making problems is in this case quite straightforward. Thus, compared to other models, the BSTS model allows us to account for uncertainty in the data and complex relationships between observed variables.
The fitting of structural time series models is done using the Kalman filter and the Markov chain Monte Carlo method (MCMC). To estimate and simultaneously regularize the regression coefficients, the so-called spike-and-slab regression, a type of Bayesian linear regression in which a particular hierarchical a priori distribution for the regression coefficients is chosen so that only a subset of possible regressors is retained. Some regression coefficients are assigned a high a priori probability that they are zero. Subsequently, MCMC sampling of the coefficients from the resulting posterior distributions reveals many coefficients to be exactly zero. This regularization mechanism allows us to efficiently select the most important predictors and in parallel to get rid of multicollinearity, so that a large number of predictors can be included in Bayesian structural models without the risk of overtraining.
Software experiments
The applicability of the BSTS model to estimate the parameters of the temperature time series was investigated in software experiments. In the experiment, we used temperature data in Tomsk for the last 5 years, received from the All-Russian Research Institute for Hydrometeorological Information — World Data Center (RIHMI-WDC) [9]. That is, the object of the study was a time series composed of average daily air temperatures in Tomsk for the period from 2017 to 2022 (Fig. 1). The statistical modeling language R and bsts package were used as tools [10].
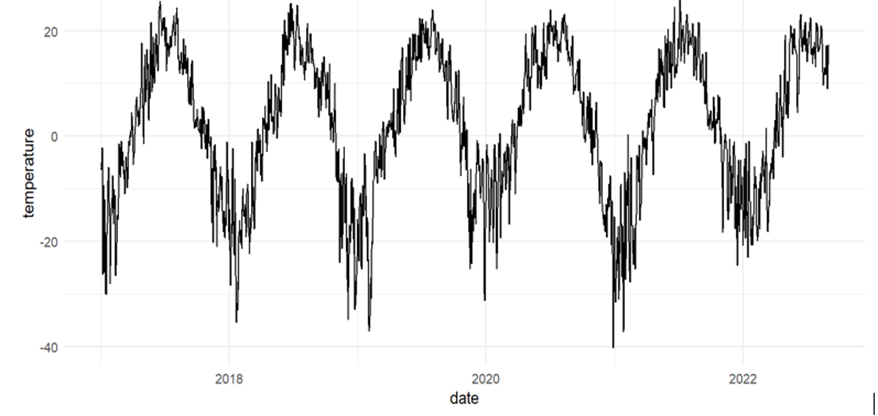
Figure 1. Average daily air temperatures in Tomsk
First, import the data and present it as a time series.
|
mydata3 <- read_excel("E:/Desktop/456.xlsx", col_types = c("date“, “numeric”)) %>% as_tsibble(., key = NULL, index = time, regular = FALSE) |
Next, we decompose the time series to understand its structure.
|
de <- decompose(mydata3) plot(de) |
Figure 2 shows the result of decomposition of this series. The figure shows that this series has an obvious annual seasonality, but no significant trend.
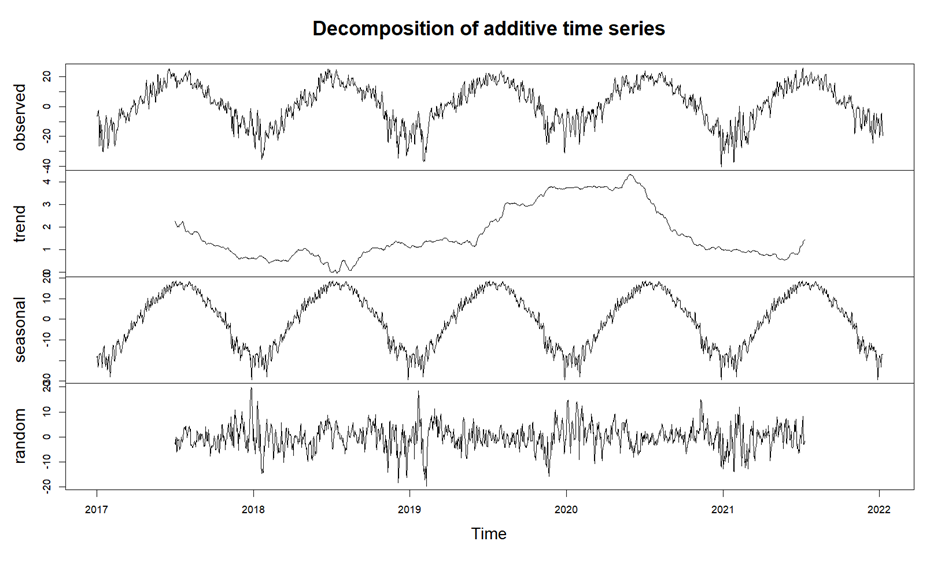
Figure 2. The result of time series decomposition
Then we split the data into a training sample and a validation sample (Fig. 3). The forecast period is set to 200 days.
|
mydata3 <- read_excel("E:/Desktop/456.xlsx", col_types = c("date“, “numeric”)) %>% as_tsibble(., key = NULL, index = time, regular = FALSE) de <- decompose(mydata3) plot(de) temp <- mydata3 %>% index_by(dt = as.Date(time)) %>% summarise(y = temperature) cut_point <- as.Date(max(temp$dt)) — 200 #training time — 200 days temp_train <- temp %>% filter(as.Date(dt) <= cut_point) temp_test <- temp %>% filter(as.Date(dt) > cut_point) dplyr::bind_rows(mutate(temp_train, dataset = “train”), mutate(temp_test, dataset = “test”)) %>% ggplot(aes(dt, y, col = dataset)) + geom_line() + geom_point(alpha = 0.4) + theme_minimal() + scale_color_manual(values = c("blue“, “black”)) temp_1 <- temp_train$y dt_1 <- temp_train$dt |
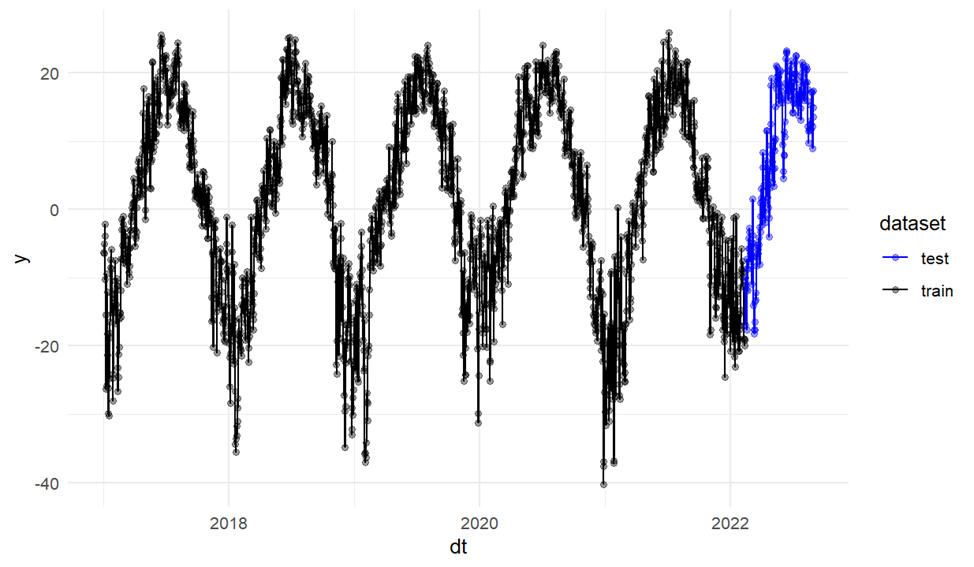
Figure 3. Training and test samples
Next comes the fitting of the model.
|
ss <- list() ss <- AddSeasonal(ss, temp_1, nseasons=12,season.duration = 30) ss <- AddAutoAr(ss,temp_1,lags = 2) M4.5<- bsts(temp_1, ss, timestamps = dt_1, niter = 700,ping = 50, seed = 511) plot(M4.5) |
Figure 4 shows the result of the model fitting.
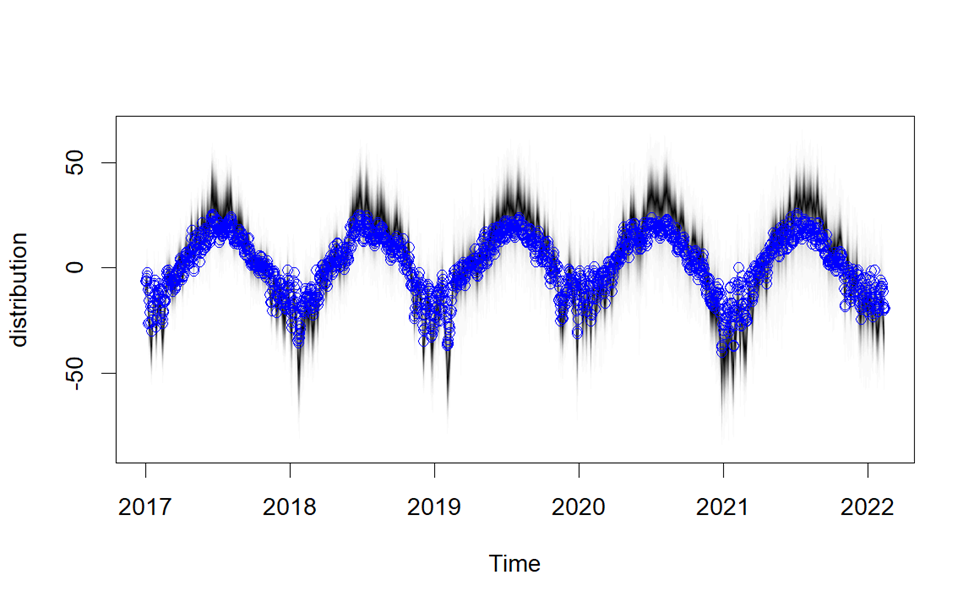
Figure 4. Result of model fitting
|
M_pred<- predict(M4.5, horizon = 200) plot(M_pred,ylim = c(-50,50),plot.original = 50) with(temp_test, points(dt, y, pch = 200, col = “yellow”)) |
Next are the forecast and the visual assessment of the forecast. Figure 5 shows the result of the forecast. Blue represents the forecast. In yellow are the data from the validation sample.
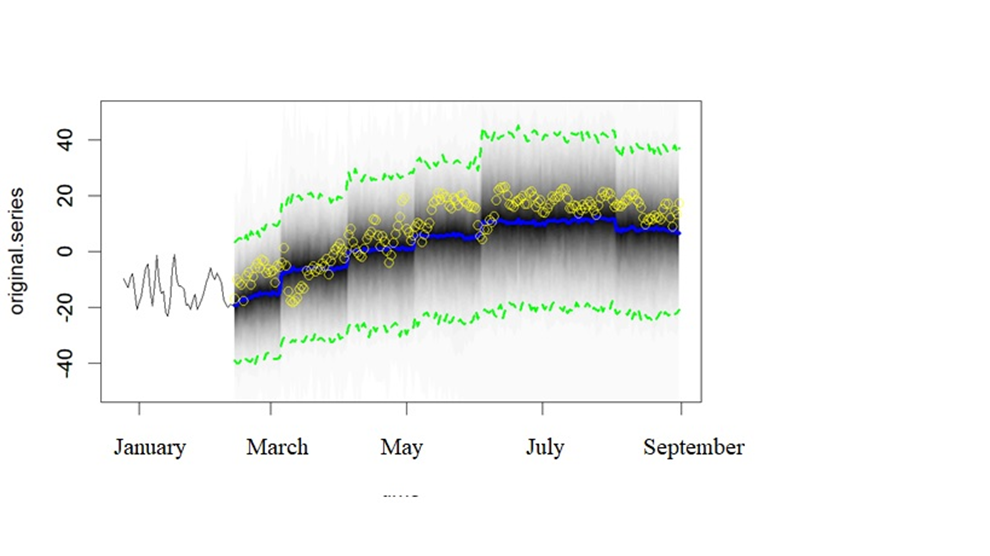
Figure 5. Forecast result
Next, we calculate the mean absolute specific error (MAPE).
|
mape <- function(observed, predicted){ mean(abs(observed — predicted)/observed) } sapply(list("M4.5″ = M_pred_4.5), mape, observed = temp_test$y ) %>% round(., 5) |
Figure 6 shows the resulting error value.

Figure 6. Mean absolute specific error
Conclusion
A software experiment scheme was developed to build and study a Bayesian structural time series model (BSTS-model). The data was sampled from long-term observations of surface atmospheric temperature in Tomsk. The statistical modeling language R and the package bsts (Bayesian Structural Time Series), a package for computing time series regression using dynamic linear models and a Monte Carlo fit based on the Markov chain method (MCMC), were used as the toolbox. Bayesian inference is a very efficient method for time series analysis, but there are many features in the BSTS model that have yet to be explored.
References:
1. Bayesian structural time series // wiki5.ru. URL: https://wiki5.ru/wiki/Bayesian_structural_time_series (accessed 14.04.2023).
3. Domanov A. O. Foundations of a Bayesian approach to quantitative analysis (on the example of Euroscepticism) // Political Science. — 2021. — № 1. — pp.
4. Masticki S. E. Time series analysis with R // ranalytics.github.io. [2020]. URL: https://ranalytics.github.io/tsa-with-r (accessed 14.04.2023).
5. Scott S. L., Varian H. R. Predicting the present with Bayesian structural time series // people.ischool.berkeley.edu. URL: https://people.ischool.berkeley.edu/~hal/Papers/2013/pred-present-with-bsts.pdf (accessed 14.04.2023).
6. Scott S. L., Varian H. R. Bayesian variable selection for nowcasting economic time series // nber.org. URL: https://www.nber.org/system/files/chapters/c12995/c12995.pdf (accessed 14.04.2023).
7. Brodersen K. H., Gallusser F., Koehler J., Remy N., Scott S. L. Inferring causal impact using Bayesian structural time-series models // Annals of Applied Statistics. — 2015. — vol. 9. — pp.
8. Guseva M. E., Silaev A. M. The Use of Bayesian Methods for Macroeconomic Modelling of Business Cycle Phases // Vestnik of Saint Petersburg University. Economics. — 2021. — Т. 37. — Vol. 2. — pp.
9. Specialised arrays // meteo.ru. URL: http://meteo.ru/data (accessed 14.04.2023).
10. Package “bsts” // cran.r-project.org. URL: https://cran.r-project.org/web/packages/bsts/bsts.pdf (accessed 14.04.2023).






