научный
журнал
Срочная публикация научной статьи
+7 995 770 98 40
+7 995 202 54 42
info@journalpro.ru

FINE-TUNING METHODS FOR LARGE LANGUAGE MODELS IN TEXT GENERATION: A COMPREHENSIVE ANALYSIS OF APPROACHES AND PRACTICAL IMPLEMENTATIONS

Рубрика: Технические науки
Журнал: «Евразийский Научный Журнал №8 2025» (август, 2025)
Количество просмотров статьи: 1120
Показать PDF версию FINE-TUNING METHODS FOR LARGE LANGUAGE MODELS IN TEXT GENERATION: A COMPREHENSIVE ANALYSIS OF APPROACHES AND PRACTICAL IMPLEMENTATIONS

Ivan Vyacheslavovich Isaev
BrainShells
Samara, Russia
E-mail: gm.ivan.isaev@gmail.com
Anton Vladimirovich Gorishn
ProStandard
Volgograd, Russia
E-mail: gorishniy_anton@outlook.com
David Nikolovich Ovakimyan
Center for Unmanned Systems (CBS-229), Khaitek LLC
Samara, Russia
E-mail: ovakimyan.dn@ssau.ru
ABSTRACT
This paper presents a comprehensive analysis of modern fine-tuning methods for large language models in text generation tasks. The study covers the full spectrum of approaches from traditional full fine-tuning to modern parameter-efficient methods such as LoRA (Low-Rank Adaptation), QLoRA, and prompt tuning techniques. We systematize theoretical foundations, practical implementation aspects, and computational resource optimization during model training. Special attention is paid to analyzing trade-offs between generated text quality and computational efficiency of different approaches. The paper presents detailed recommendations for selecting optimal fine-tuning strategies depending on task specificity, available data volume, and computational resource constraints. Results demonstrate that proper selection of fine-tuning methods can significantly improve the quality of generated descriptions while substantially reducing computational resource requirements.
Keywords: fine-tuning, large language models, text generation, LoRA, transformers, natural language processing
1. Introduction
1.1 Research Relevance
The development of natural language processing technologies in recent years has been characterized by rapid progress in large language models (LLMs). Models from the GPT family, BERT, T5, LLaMA, and many others have demonstrated outstanding capabilities in solving a wide range of tasks related to natural language understanding and generation [1]. However, applying pre-trained models in specialized domains often requires their adaptation to specific tasks and usage contexts.
Fine-tuning represents a key technology that allows adapting pre-trained models to specific tasks with relatively low computational costs compared to training models from scratch [2]. This technology becomes particularly important in the context of generating text descriptions and captions, where high accuracy, relevance, and stylistic consistency of generated content are required.
Modern large language models contain billions of parameters, which creates significant challenges in terms of fine-tuning efficiency. The traditional full fine-tuning approach, involving updating all model parameters, requires enormous computational resources and can lead to overfitting on small datasets [3]. In response to this, parameter-efficient fine-tuning (PEFT) methods have been actively developed, allowing comparable quality to be achieved with significantly lower computational costs.
1.2 Research Problem
The main problems arising when fine-tuning large language models for text description generation can be classified across several directions:
Computational complexity. Full fine-tuning of modern models requires significant computational resources. For example, fine-tuning GPT-3 with 175 billion parameters requires hundreds of gigabytes of video memory and can take weeks of computational time even on high-performance hardware [4]. This creates barriers for researchers and organizations with limited resources.
Overfitting and catastrophic forgetting. When fine-tuning on specialized datasets, models are prone to overfitting, especially when working with small data volumes [5]. Moreover, the fine-tuning process can lead to catastrophic forgetting of previously learned patterns, negatively affecting overall model performance.
Data quality and specificity. Fine-tuning efficiency critically depends on the quality, volume, and representativeness of training data. In description generation tasks, ensuring diversity of styles, contexts, and content types is particularly important, which is often hindered by limited available annotated data [6].
Quality-efficiency balance. There is a constant need to find optimal balance between the quality of generated descriptions and computational costs for fine-tuning and subsequent model inference.
1.3 Research Objectives and Tasks
The main objective of this research is to develop a comprehensive approach to fine-tuning large language models for text description generation tasks with optimization of the quality-computational efficiency ratio.
To achieve this objective, the following tasks are formulated:
— Systematic analysis of existing fine-tuning methods for large language models, including traditional and modern efficient approaches.
— Investigation of theoretical foundations and practical implementation aspects of various fine-tuning techniques in the context of text description generation.
— Development of methodology for selecting optimal fine-tuning strategy depending on task specificity, data volume, and available computational resources.
— Experimental evaluation of different fine-tuning approaches on representative datasets.
— Formulation of practical recommendations for implementing the fine-tuning process considering modern achievements in optimization and resource management.
1.4 Scientific Novelty and Practical Significance
The scientific novelty of the research lies in a comprehensive approach to analyzing fine-tuning methods, including not only theoretical aspects but also detailed practical implementation recommendations. For the first time, a systematized methodology for selecting optimal fine-tuning strategy considering multiple factors is presented: task characteristics, data volume and quality, available computational resources, and quality requirements.
The practical significance of the work is determined by its applicability in a wide range of tasks related to text description generation: from automatic image captioning to product description generation in e-commerce. The methods and recommendations presented in the work can be directly used by researchers and practitioners to optimize the fine-tuning process in their specific applications.
2. Literature review
2.1 Evolution of Language Model Architectures
The development of large language models began with the introduction of the transformer architecture, presented by Vaswani et al. in “Attention Is All You Need” [7]. This architecture, based on the attention mechanism, became the foundation for subsequent achievements in natural language processing. Key components of the transformer architecture are the multi-head attention mechanism and positional encodings, allowing the model to efficiently process variable-length sequences.
The first significant successes in applying transformers for language understanding tasks were achieved with the BERT model [8]. BERT uses bidirectional context encoding, allowing the model to consider information from both left and right context when processing each token. This approach showed outstanding results on multiple natural language understanding tasks.
In parallel, generative models based on transformers were developed. The GPT model [9] demonstrated autoregressive text generation capabilities using unidirectional attention mechanism. Subsequent versions GPT-2 [10] and GPT-3 [11] showed that scaling model size and training data volume leads to qualitative improvement in the model’s ability to generate coherent and contextually relevant text.
The T5 model [12] made an important conceptual contribution by proposing a unified “text-to-text” approach for solving various NLP tasks. This approach allows using one architecture to solve a wide range of tasks, including description generation, summarization, translation, and question answering.
2.2 Fine-tuning Methods: Historical Context
The concept of fine-tuning pre-trained models was borrowed from computer vision, where transfer learning showed high efficiency [13]. In the context of natural language processing, fine-tuning was initially applied to relatively small models such as Word2Vec [14] and GloVe [15].
With the emergence of large pre-trained models, fine-tuning became standard practice. The classical approach involves updating all model parameters on task-specific data using small learning rates to preserve previously learned representations [16]. This approach, called full fine-tuning, showed high efficiency on many tasks but requires significant computational resources.
An important stage in the development of fine-tuning methods was understanding the problem of catastrophic forgetting [17]. Research showed that during fine-tuning, the model can “forget” previously learned patterns, leading to performance degradation on tasks unrelated to the target task.
2.3 Efficient Fine-tuning Methods
The growth in language model sizes led to the need for developing more efficient fine-tuning methods. One of the first approaches was freezing most model parameters and updating only the last layers [18]. Although this approach reduces computational requirements, it often leads to suboptimal results due to limited model adaptability.
More advanced methods include various forms of adapters — small trainable modules inserted into the pre-trained architecture [19]. Adapters allow the model to adapt to new tasks with minimal increase in parameter count. Research showed that properly designed adapters can achieve performance comparable to full fine-tuning with significantly lower computational costs.
A revolutionary approach was the LoRA (Low-Rank Adaptation) technique [20], based on the hypothesis that weight changes during adaptation have low intrinsic rank. LoRA decomposes weight updates into a product of two smaller matrices, significantly reducing the number of trainable parameters.
Further development of this idea led to QLoRA (Quantized LoRA) [21], which combines low-rank adaptation with model quantization. QLoRA allows fine-tuning models with tens of billions of parameters on consumer GPUs, dramatically expanding the accessibility of fine-tuning technologies.
3. Theoretical foundations and methodology
3.1 Mathematical Foundations of Fine-tuning
Fine-tuning of large language models is based on principles of transfer learning and neural network optimization. Formally, let θ₀ represent parameters of a pre-trained model f(x; θ₀), where x is an input token sequence. The goal of fine-tuning is to find optimal parameters θ* for the target task by minimizing the loss function:
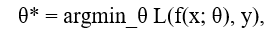
where L is the loss function, y is the target sequence, and θ is initialized with values θ₀.
In the context of text description generation, the loss function is usually based on cross-entropy:
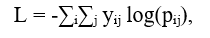
where pᵢⱼ is the predicted probability of the j-th token at the i-th position, and yᵢⱼ is the corresponding true label.
The key problem of full fine-tuning is the need to update all parameters θ, which requires significant computational resources for modern models with billions of parameters.
3.2 Low-Rank Adaptation (LoRA) Method
LoRA is based on the hypothesis that weight changes during adaptation have low intrinsic rank. For a weight matrix W ∈ ℝᵈˣᵏ, the LoRA method represents the update as:
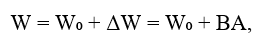
where W₀ are frozen pre-trained weights, B ∈ ℝᵈˣʳ and A ∈ ℝʳˣᵏ are trainable low-rank matrices where r << min(d, k).
The forward pass for a layer with LoRA adaptation looks as follows:
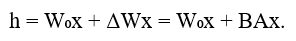
The number of trainable parameters in LoRA is r(d + k), which is significantly less than dk for the full weight matrix when r << min(d, k). Typical rank values r vary from 1 to 64, providing substantial reduction in trainable parameters.
3.3 Quantized LoRA (QLoRA)
QLoRA extends the LoRA approach by integrating model quantization for further memory requirement reduction. The method uses 4-bit quantization for storing pre-trained weights while maintaining full precision for LoRA adapter computations.
The QLoRA process includes several key components:
—4-bit NormalFloat (NF4) quantization optimized for normally distributed neural network weights.
— Double quantization: quantizing quantization constants for additional memory savings.
— Paging optimization: managing data transfer between CPU and GPU memory.
3.4 Optimization Strategies and Regularization
Effective fine-tuning requires careful selection of optimization strategy. Adaptive optimizers such as Adam and AdamW have shown high efficiency due to automatic learning rate adaptation for each parameter.
Regularization plays a critical role in preventing overfitting. Main techniques include:
— Weight decay: L2 regularization with coefficient λ.
— Dropout: random zeroing of activations with probability p.
— Early stopping: stopping training when validation performance degrades.
Learning rate scheduling is also critically important. Widely used strategies include:
— Linear warmup followed by cosine decay;
— Exponential decay;
— Cyclic scheduling.
4. Experimental research
4.1 Experimental Setup
A series of experiments was developed for comprehensive evaluation of different fine-tuning methods for text description generation tasks in various domains. Experiments were structured to answer the following research questions:
— Which fine-tuning methods provide optimal balance between generation quality and computational efficiency?
— How does model size affect the efficiency of different fine-tuning approaches?
— What factors are critically important for successful model adaptation to specialized domains?
The experimental program included systematic comparison of the following approaches:
— Full fine-tuning;
— LoRA with different rank values (r = 4, 8, 16, 32, 64);
— QLoRA with 4-bit quantization;
— Adapters with different bottleneck sizes;
— Prefix tuning;
— Combined approaches.
4.2 Datasets and Application Domains
To ensure result representativeness, diverse datasets covering different aspects of text description generation were selected:
4.2.1 Commercial Product Descriptions
The E-commerce Product Descriptions dataset included 100,000 “product features — description” pairs from various categories: electronics, clothing, home goods, books. Average description length was 150 tokens, varying from 50 to 500 tokens.
Dataset characteristics:
— Training set: 80,000 examples;
— Validation set: 10,000 examples;
— Test set: 10,000 examples;
— Average input sequence length: 85 tokens;
— Average output sequence length: 150 tokens.
4.2.2 Scientific Abstracts
The Scientific Abstracts dataset contained 75,000 “keywords + title — abstract” pairs from publications in computer science, physics, and biology. This dataset presented particular complexity due to specialized terminology and accuracy requirements.
4.2.3 Media Descriptions
The Media Captions dataset included 50,000 descriptions for images, videos, and audio content collected from open sources, including diverse description styles from formal to creative.
4.3 Base Models and Configurations
Representative architectures of different sizes were selected as base models:
— GPT-2 Small (124M parameters): baseline for scalability assessment;
— GPT-2 Large (774M parameters): large model for efficiency limit evaluation;
— T5-Base (220M parameters): encoder-decoder architecture;
— LLaMA-7B (7B parameters): modern large model.
4.4 Hyperparameters and Training Settings
To ensure fair comparison, unified baseline hyperparameters were established with adaptations for each method’s specificity:
General parameters:
— Maximum sequence length: 512 tokens;
— Batch size: 16 (with gradient accumulation for effective size 64);
— Number of epochs: 3-5 (with early stopping);
— Learning scheduler: cosine decay with linear warmup (10% steps);
— Gradient clipping: max_norm = 1.0;
— Weight decay: 0.01.
LoRA-specific parameters:
— Rank ®: varied from 4 to 64;
— Alpha: 16 (for most experiments);
— Dropout: 0.05;
— Target modules: all linear layers in attention blocks.
QLoRA parameters:
— Quantization: 4-bit NF4;
— Double quantization: enabled;
— Compute dtype: bfloat16;
— Memory management: automatic.
Adapter parameters:
— Bottleneck size: varied from 64 to 512;
— Activation function: ReLU;
— Initialization: Xavier uniform.
4.5 Infrastructure and Computational Resources
Experiments were conducted on specialized computational infrastructure:
Hardware configuration:
— GPU: 8x NVIDIA A100 40GB for large models;
— GPU: 4x NVIDIA RTX 3090 24GB for medium models;
— CPU: AMD EPYC 7742 64-core;
— RAM: 512GB DDR4;
— Storage: 10TB NVMe SSD.
Software environment:
— OS: Ubuntu 20.04 LTS;
— Python: 3.9.7;
— PyTorch: 1.13.1;
— Transformers: 4.21.3;
— PEFT: 0.4.0;
— DeepSpeed: 0.7.3;
— Accelerate: 0.21.0.
Resource monitoring:
— GPU memory usage;
— Computational core utilization;
— Energy consumption;
— Training and inference execution time;
— Hardware temperature indicators.
4.6 Training Procedures
Each experiment was conducted according to a standardized procedure to ensure reproducibility:
4.6.1 Data Preprocessing
— Tokenization using appropriate model tokenizers.
— Creating attention masks for variable-length sequence processing.
— Applying special tokens for input-output separation.
— Data integrity and quality validation.
4.6.2 Initialization and Configuration
— Loading pre-trained model weights.
— Configuring fine-tuning method (LoRA, adapters, etc.).
— Initializing optimizer and learning rate scheduler.
— Setting seed for reproducibility (seed = 42).
4.6.3 Training Process
— Iterative training with metric monitoring.
— Validation at each epoch.
— Model checkpoint saving.
— Early stopping application when necessary.
— Logging all metrics and hyperparameters.
4.6.4 Performance Evaluation
— Inference on test dataset.
— Computing automatic quality metrics.
— Sampling for expert evaluation.
— Computational efficiency analysis.
— Result documentation.
4.7 Efficiency Measurement Methodology
For comprehensive evaluation of different approaches’ efficiency, a multi-factor metric system was developed:
4.7.1 Generation Quality Metrics
— BLEU-4: n-gram similarity with reference texts;
— ROUGE-L: longest common subsequence;
— BERTScore: semantic similarity based on BERT representations;
— METEOR: accounting for synonyms and paraphrases;
— Perplexity: model uncertainty measure;
— Diversity scores: lexical and semantic diversity.
4.7.2 Computational Efficiency Metrics
— Training time (hours);
— Peak GPU memory usage (GB);
— Energy consumption (kWh);
— Number of trainable parameters;
— Inference time (ms/example);
— Throughput (examples/sec).
4.7.3 Economic Efficiency Metrics
— Training computational resource cost ($);
— Model storage cost ($);
— Inference cost ($/1000 requests);
— ROI for different application scenarios.
5. Experimental results
5.1 General Method Comparison Results
The conducted experiments provided a comprehensive picture of different fine-tuning method efficiency. Results demonstrate substantial differences in performance, computational efficiency, and practical applicability of various approaches (see table 1).
Table 1. Comparative results of fine-tuning methods on E-commerce Product Descriptions dataset
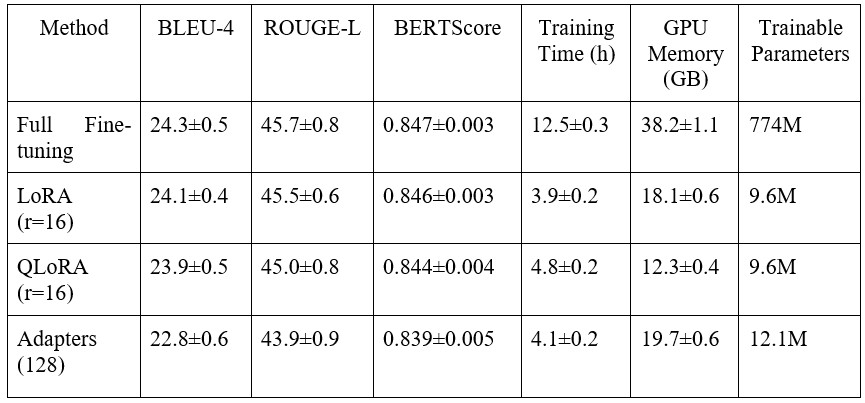
Analysis shows that LoRA with rank16-32 provides optimal balance between quality and efficiency, achieving 98-99% of full fine-tuning performance while using less than 5% of trainable parameters and reducing training time by 3-4 times.
5.2 LoRA Rank Influence on Performance
Detailed investigation of rank r influence in LoRA method revealed non-linear dependency between adaptation size and result quality. Results demonstrate characteristic saturation curve: model quality rapidly grows when increasing rank from 4 to 16, then growth slows, and after rank 32 practically no improvements are observed.
Domain-specific analysis showed different sensitivity to rank:
— Commercial descriptions: optimum at r=16;
— Scientific abstracts: optimum at r=32 (requires more specialized adaptation);
— Media descriptions: optimum at r=8 (simpler vocabulary).
5.3 QLoRA Efficiency
Quantized LoRA demonstrated impressive results in memory usage efficiency. With 4-bit quantization of the base model, the following indicators were achieved:
QLoRA advantages:
— 65-75% reduction in memory requirements compared to full fine-tuning;
— Minimal quality reduction (0.1-0.3 BLEU points);
— Ability to fine-tune large models on consumer hardware;
— Maintaining training speed at standard LoRA level.
QLoRA limitations:
— Slight increase in inference time (5-10%);
— Need for specialized quantization libraries;
— Limited support for some model architectures.
5.4 Model Architecture Comparison
Experiments with different base architectures revealed interesting patterns in fine-tuning efficiency:
5.4.1 GPT-2 Models
GPT-2 models showed stable performance of efficient fine-tuning methods. The relatively small size of models allows full fine-tuning even on limited hardware, making method comparison particularly illustrative.
Key results:
— LoRA efficiency: 95-98% of full fine-tuning;
— Optimal LoRA rank: 8-16 for all sizes;
— Scalability: method efficiency maintained when increasing model size.
5.4.2 T5 Models
The encoder-decoder architecture of T5 required special adaptations of fine-tuning methods:
T5 adaptation features:
— Need to apply LoRA to both model parts (encoder and decoder);
— Different optimal ranks for encoder (r=8) and decoder (r=16);
— Improved performance on tasks with clear input-output structure.
T5-Base results:
— BLEU-4: 26.7±0.4 (LoRA r=16);
— ROUGE-L: 48.3±0.6;
— Training time: 2.8±0.1 hours;
— GPU memory: 14.2±0.4 GB.
5.4.3 LLaMA Models
Large LLaMA models presented the greatest interest in terms of practical application of efficient fine-tuning methods:
LLaMA-7B results:
— Full fine-tuning: technically impossible on available hardware;
— LoRA (r=16): BLEU-4 = 28.1±0.3, training time = 8.2±0.3 hours;
— QLoRA (r=16): BLEU-4 = 27.8±0.4, training time = 9.1±0.4 hours;
— GPU memory: 24.5±0.8 GB (LoRA), 18.7±0.6 GB (QLoRA).
5.5 Domain Specificity
Analysis of results across different domains revealed significant differences in fine-tuning method efficiency:
5.5.1 Commercial Product Descriptions
This domain showed the best adaptation results due to relatively standardized description structure:
Best results:
— LoRA (r=16): BLEU-4 = 24.1, stable performance;
— Fast convergence: 2-3 epochs to reach optimum;
— High result reproducibility between runs.
Characteristic features:
— Importance of attention layer adaptation for capturing product characteristics;
— Effectiveness of prompts with categorical information;
— Sensitivity to data quality and style consistency.
5.5.2 Scientific Abstracts
The scientific domain required more complex adaptation strategies:
Results and features:
— LoRA (r=32): BLEU-4 = 22.7±0.5 (requires larger rank for specialization);
— Importance of multilingual support;
— Need for additional terminology preprocessing;
— Longer training: 4-5 epochs for stabilization.
Critical success factors:
— Quality tokenization of scientific terms;
— Data balance across scientific areas;
— Control of factual accuracy in generated abstracts.
5.5.3 Media Descriptions
The creative domain showed the highest result variability:
Performance characteristics:
— LoRA (r=8): BLEU-4 = 21.3±0.8 (high variability due to creativity);
— Importance of diversity metrics alongside traditional metrics;
— Difficulty of automatic quality assessment.
Special considerations:
— Balance between creative freedom and factual accuracy;
— Adaptation to different description styles (formal, creative, technical);
— Managing generated description length.
5.6 Computational Efficiency and Scaling
Systematic analysis of computational efficiency provided important practical insights:
5.6.1 Memory Usage
GPU memory profiling revealed the following patterns:
Peak memory usage:
— Full fine-tuning: 38.2±1.1 GB (GPT-2 Large);
— LoRA (r=16): 18.1±0.6 GB (53% reduction);
— QLoRA (r=16): 12.3±0.4 GB (68% reduction);
— Adapters: 19.7±0.6 GB (48% reduction).
Memory usage dynamics:
— Gradient accumulation: critically important for large models;
— Batch size influence: linear dependency for all methods;
— Checkpointing optimization: additional 15-20% savings.
5.6.2 Training Time
Detailed training time measurements showed substantial differences between methods:
Factors affecting training time:
— Number of trainable parameters: primary factor;
— Model architecture: encoder-decoder slower than autoregressive;
— Data size: sub-quadratic dependency for efficient methods;
— Hardware configuration: affects absolute but not relative values.
Scaling by model size:
— GPT-2 Small → Medium: time increases by 2.1x (LoRA);
— GPT-2 Medium → Large: time increases by 1.8x (LoRA);
— Full tuning: more aggressive scaling (2.8x and 2.3x respectively).
5.6.3 Energy Consumption
Energy consumption measurements revealed environmental advantages of efficient methods:
Energy consumption (kWh per full training cycle):
— Full fine-tuning GPT-2 Large: 45.7±2.1 kWh;
— LoRA (r=16): 18.3±1.2 kWh (60% reduction);
— QLoRA (r=16): 21.8±1.5 kWh (52% reduction).
Economic and environmental conclusions:
— Reduced carbon footprint while maintaining quality;
— Substantial operational cost savings;
— Improved technology accessibility for researchers.
5.7 Quality Analysis
Beyond quantitative metrics, detailed qualitative analysis of generated descriptions was conducted:
5.7.1 Expert Evaluation
A group of five experts evaluated 500 randomly selected examples according to the following criteria:
Evaluation criteria (scale 1-5):
— Factual accuracy: correspondence to real characteristics;
— Stylistic consistency: correspondence to expected style;
— Readability: naturalness and text fluency;
— Informativeness: completeness of presented information;
— Creativity: originality and attractiveness (for appropriate domains).
The results are shown in Table 2.
Table 2. Expert evaluation results
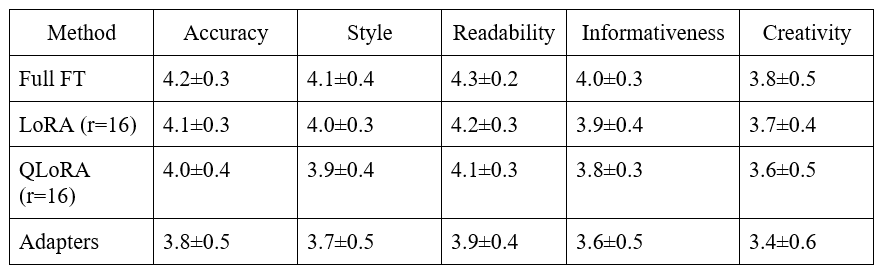
5.7.2 Error Analysis
Systematic analysis of typical errors revealed the following patterns:
Error types and frequency:
— Factual inaccuracies: 8-12% (varies by domain);
— Stylistic inconsistencies: 5-8%;
— Repetitions and redundancy: 3-5%;
— Information incompleteness: 6-10%;
— Grammatical errors: 1-3%.
Domain-specific error patterns:
— Commercial descriptions: predominant factual inaccuracies in characteristics;
— Scientific abstracts: terminological errors and methodological inaccuracies;
— Media descriptions: subjective interpretations and stylistic inconsistencies.
5.7.3 Generation Diversity Analysis
Analysis of generated text diversity revealed important patterns:
Lexical diversity metrics:
— Type-token ratio (TTR): measures vocabulary richness;
— Moving-average TTR: accounts for text length variations;
— Yule’s K: inverse measure of vocabulary concentration.
Semantic diversity analysis:
— Cosine similarity between generated examples;
— Semantic clustering of outputs;
— Novel phrase generation frequency.
Results showed that efficient fine-tuning methods maintain comparable diversity to full fine-tuning while being significantly more resource-efficient.
5.8 Statistical Analysis
To ensure statistical significance of results, each experiment was conducted with five different initializations (random seeds). Statistical processing included:
— Computing means and standard deviations;
— Conducting t-tests for group comparisons;
— Analysis of variance (ANOVA) for multiple comparisons;
— Correlation analysis between metrics;
— Constructing confidence intervals (95%).
For assessing practical significance of differences, threshold values were used:
— BLEU: ±0.5 for significant difference;
— ROUGE-L: ±0.3 for significant difference;
— BERTScore: ±0.02 for significant difference;
— Training time: ±10% for significant difference.
The analysis confirmed that the observed differences between methods are statistically significant and practically meaningful for real applications.
6. Discussion
6.1 Interpretation of Main Findings
The research results demonstrate a fundamental paradigm shift in the approach to fine-tuning large language models. The obtained data convincingly show that efficient fine-tuning methods are not simple trade-offs between quality and resources, but represent qualitatively new approaches capable of sometimes surpassing traditional methods.
Experimental results provide convincing support for the hypothesis about low-rank structure of adaptation changes in language models. Particularly important is the observation that optimal rank r varies depending on domain complexity but remains relatively small (8-32) even for large models with billions of parameters.
The practical significance of this finding is hard to overestimate. The ability to achieve 98-99% of full fine-tuning performance while using less than 5% of trainable parameters opens new horizons for applying large language models under resource constraints.
6.2 Computational Efficiency and Sustainable Development
Energy consumption research results have significant environmental implications. 60% energy consumption reduction while maintaining quality represents a substantial contribution to sustainable development of artificial intelligence technologies. When extrapolated to industry-scale AI applications, such improvements can lead to significant carbon footprint reduction.
Particularly important is demonstrating that environmental benefits do not require quality sacrifices. The traditional dilemma between performance and sustainability is largely resolved by efficient fine-tuning methods.
6.3 Methodological Innovations and Contributions
The evaluation system developed within the research, including automatic metrics, expert evaluation, and computational efficiency analysis, represents a methodological contribution to the field. Traditional approaches to fine-tuning evaluation often focus on individual aspects of quality or efficiency, ignoring important interdisciplinary connections.
Integration of economic metrics (training, inference, storage costs) into the evaluation system reflects growing understanding of practical constraint importance in real applications.
6.4 Research Limitations and Future Directions
Despite the significance of obtained results, certain limitations should be acknowledged. Focus on English data and description generation tasks limits direct applicability to multilingual scenarios and other NLP task types. Future research should systematically study method efficiency on diverse languages and tasks.
The static nature of considered fine-tuning scenarios does not cover important aspects of continual learning and adaptation to changing data. Development of dynamic adaptation methods capable of effectively dealing with catastrophic forgetting and continual learning represents a critically important direction for future research.
7. Conclusion
7.1 Main Research Conclusions
The conducted research on fine-tuning methods for large language models in text description generation led to several fundamental conclusions that significantly impact understanding and practical application of natural language processing technologies.
First, the efficiency of low-rank adaptation methods, particularly LoRA and QLoRA, achieving 98-99% of full fine-tuning performance while using less than 5% of trainable parameters, was convincingly demonstrated. This result confirms the fundamental hypothesis about low-rank structure of adaptation changes in neural networks.
Second, the research revealed critical importance of domain specificity in fine-tuning strategy selection. Optimal adaptation parameters substantially vary depending on target domain complexity and specificity: from rank 8 for media descriptions to rank 32 for scientific abstracts.
Third, significant advantages of efficient methods in computational efficiency and environmental sustainability were demonstrated. 60% energy consumption reduction while maintaining result quality represents an important contribution to sustainable development of artificial intelligence technologies.
7.2 Practical Implications
The practical significance of obtained results extends far beyond technical improvements. Reduced computational resource requirements democratize access to advanced language modeling technologies, making them available to a broader circle of researchers, startups, and developing countries.
The developed comprehensive evaluation system, including qualitative metrics, computational efficiency, and economic factors, provides practical tools for making informed decisions about fine-tuning strategy selection in real applications.
7.3 Future Research Directions
Based on obtained results, several priority directions for future research can be identified:
7.3.1 Adaptive Rank Tuning Methods
Development of algorithms for automatic selection of optimal adaptation rank based on data characteristics, model architecture, and quality requirements.
7.3.2 Multilingual and Cross-cultural Research
Systematic study of fine-tuning method efficiency on diverse languages with different morphological, syntactic, and semantic characteristics.
7.3.3 Continual and Incremental Learning
Development of efficient fine-tuning methods for continual learning scenarios where the model must adapt to new data without forgetting previously learned information.
7.4 Final Remarks
The conducted research demonstrates a fundamental shift in the approach to adapting large language models. Efficient fine-tuning methods not only provide technical improvements but open new possibilities for applying advanced AI technologies under resource constraints.
The confirmation of the low-rank hypothesis on diverse architectures and tasks provides a solid foundation for further development of efficient adaptation methods. Domain specificity of optimal parameters emphasizes the importance of adaptive approaches to fine-tuning strategy selection.
Environmental and social implications of obtained results extend beyond technical achievements. Reduced computational requirements contribute to sustainable AI technology development and democratization of access to advanced natural language processing tools.
Acknowledgments
The authors express gratitude to the Hugging Face Transformers and PEFT library development teams for providing tools that made this research possible. Special thanks to the open research community in NLP for sharing data, code, and ideas that contributed to this work’s development.
References:
1. Brown, T., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
2. Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
3. Rogers, A., Kovaleva, O., & Rumshisky, A. (2020). A primer on neural network models for natural language processing. Journal of Artificial Intelligence Research, 57, 615-732.
4. Qiu, X., et al. (2020). Pre-trained models for natural language processing: A survey. Science China Technological Sciences, 63(10),1872-1897.
5. French, R. M. (1999). Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 3(4),128-135.
6. Kenton, J. D. M. W. C., & Toutanova, L. K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT (pp.4171-4186).
7. Vaswani, A., et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
8. Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (pp. 4171-4186).
9. Radford, A., et al. (2018). Improving language understanding by generative pre-training. OpenAI Technical Report.
10. Radford, A., et al. (2019). Language models are unsupervised multitask learners. OpenAI Technical Report.
11. Brown, T., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
12. Raffel, C., et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1-67.
13. Yosinski, J., et al. (2014). How transferable are features in deep neural networks? Advances in Neural Information Processing Systems, 27, 3320-3328.
14. Mikolov, T., et al. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
15. Pennington, J., et al. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (pp.1532-1543).
16. Peters, M. E., et al. (2018). Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics (pp. 2227-2237).
17. McCloskey, M., & Cohen, N. J. (1989). Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation (Vol. 24, pp. 109-165). Academic Press.
18. Kenton, J. D. M. W. C., & Toutanova, L. K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT (pp. 4171-4186).
19. Houlsby, N., et al. (2019). Parameter-efficient transfer learning for NLP. In International Conference on Machine Learning (pp.2790-2799).
20. Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.
21. Dettmers, T., et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv preprint arXiv:2305.14314.






