научный
журнал
Срочная публикация научной статьи
+7 995 770 98 40
+7 995 202 54 42
info@journalpro.ru

АРХИТЕКТУРА СИСТЕМ АВТОМАТИЧЕСКОГО ТЕХНИЧЕСКОГО АУДИТА САЙТОВ

Рубрика: Технические науки
Журнал: «Евразийский Научный Журнал №2 2026» (февраль, 2026)
Количество просмотров статьи: 211
Показать PDF версию АРХИТЕКТУРА СИСТЕМ АВТОМАТИЧЕСКОГО ТЕХНИЧЕСКОГО АУДИТА САЙТОВ
Чурилов Александр Александрович
Генеральный директор ООО «Айсео», г. Москва
E-mail: a.churilov@iseo.ru
АННОТАЦИЯ
В настоящей статье представлен унифицированный анализ систем автоматического технического аудита веб-сайтов, охватывающий их архитектурные основания, паттерны декомпозиции на микросервисы, стратегии конвейеров данных, модели хранения, проектирование движков правил, методологии оценки качества и подходы к реализации на основе открытого программного обеспечения. Опираясь на принципы эталонной архитектуры данных, нормативно-правовую базу FedRAMP, движки аудиторских правил в областях SEO, производительности, доступности и безопасности, а также каталоги инструментов с открытым исходным кодом, настоящая работа синтезирует эти перспективы в единую архитектурную концепцию. Исследование демонстрирует, что эффективные системы аудита требуют продуманного разделения ответственности на уровнях сбора, обработки, хранения и представления данных; что регуляторные фреймворки, в частности FedRAMP, устанавливают обязательные минимальные стандарты проверок безопасности; что инструменты с открытым исходным кодом, в первую очередь Google Lighthouse и Pa11y, служат практическими эталонными реализациями многодоменных движков правил. Приводится численный кейс-стади, иллюстрирующий экономическую и операционную целесообразность инвестиций в автоматизированную аудиторскую инфраструктуру в масштабе реального предприятия. Расчёты демонстрируют сокращение затрат на 87,5% и достижение точки безубыточности в течение первого года эксплуатации при одновременном увеличении частоты аудита в 90 раз и переходе от выборочной к полной проверке всех страниц.
Ключевые слова: автоматический технический аудит, микросервисная архитектура, конвейеры данных, движок правил, Core Web Vitals, WCAG, FedRAMP, SEO-аудит, аудит безопасности, Lighthouse, Pa11y, OWASP ZAP, CI/CD интеграция, управление качеством веб-ресурсов.
Keywords: automated technical audit, microservice architecture, data pipelines, rule engine, Core Web Vitals, WCAG, FedRAMP, SEO audit, security audit, Lighthouse, Pa11y, OWASP ZAP, CI/CD integration, web quality management.
ВВЕДЕНИЕ
Проблема масштаба и сложности в обеспечении качества веб-ресурсов
Современные веб-системы достигли такого уровня сложности, что ручная техническая проверка в любом осмысленном масштабе практически невозможна. Среднестатистическая платформа электронной коммерции может обслуживать десятки тысяч уникальных URL-адресов; государственный веб-портал может охватывать сотни поддоменов и тысячи документов. Каждая из этих страниц должна одновременно удовлетворять требованиям по множеству измерений качества: доступность для поисковых систем (SEO), воспринимаемая пользователем скорость загрузки, доступность для людей с ограниченными возможностями и устойчивость к угрозам безопасности. Пересечение этих требований создаёт аудиторскую поверхность, которую ни одна команда специалистов не может в полной мере охватить силами ручного труда.
Следствием этого разрыва является то, что организации либо мирятся с неконтролируемым техническим долгом в своих веб-проектах, либо полагаются на нерегулярные ручные аудиты, которые устаревают почти немедленно, либо инвестируют в автоматизированную аудиторскую инфраструктуру. Третий путь — систематический, автоматизированный, воспроизводимый технический аудит — является предметом настоящего исследования.
Актуальность темы обусловлена взрывным ростом числа веб-ресурсов и ужесточением требований к их качеству со стороны поисковых систем, регуляторов и конечных пользователей. По данным W3Techs, к 2025 году число активных веб-сайтов в мире превысило 1,1 миллиарда, тогда как команды специалистов по веб-качеству остаются ограниченными по размеру. Автоматизация аудита становится не дополнительным удобством, а стратегической необходимостью для любой организации, управляющей более чем несколькими десятками страниц.
Значимость эталонной архитектуры
Концепция эталонной архитектуры особенно ценна в данном контексте. Вместо того чтобы каждый раз строить системы аудита с нуля, эталонная архитектура предоставляет нормативную модель: общий словарь, набор проверенных структурных паттернов и чёткое разграничение ответственности компонентов. Как отмечает Стефан Фрост, ключевая ценность такой архитектуры заключается в том, что она обеспечивает «общий язык и единое понимание» для всех участников проектирования и разработки систем. Без этой общей модели команды раз за разом решают одни и те же архитектурные проблемы несовместимыми способами, создавая системы, которые трудно поддерживать, расширять или интегрировать.
Цели и структура исследования
Настоящая статья преследует пять взаимосвязанных целей: (1) установить концептуальные основы эталонной архитектуры применительно к системам автоматического аудита веб-сайтов; (2) описать основные архитектурные уровни — микросервисы, конвейеры данных, хранилища и отчётность — и их функциональные взаимосвязи; (3) проанализировать проектирование движков правил в четырёх основных доменах аудита: SEO, производительность, доступность и безопасность; (4) рассмотреть, каким образом регуляторные фреймворки, в частности FedRAMP, формализуют обязательные требования к проверкам безопасности; (5) изучить реализации с открытым исходным кодом и их роль в качестве практических эталонных точек для проектирования систем. Статья структурирована по принципу движения от фундаментальных концепций к всё более специфическим архитектурным и имплементационным вопросам, завершаясь численным кейс-стади.
1. КОНЦЕПТУАЛЬНЫЕ ОСНОВЫ
1.1. Эталонная архитектура: определение и принципы
Эталонная архитектура — это не чертёж конкретной системы. Это нормативная модель, описывающая типовые компоненты, их взаимосвязи и принципы взаимодействия для класса проблем. Различие принципиально: чертёж точно указывает, что именно строить; эталонная архитектура определяет, какого рода вещи следует строить и как они должны соотноситься друг с другом. Для систем автоматического аудита веб-сайтов это различие позволяет использовать единую концептуальную систему в организациях разного масштаба, с разными технологическими стеками, аудирующих различные типы веб-ресурсов — при этом давая конкретные рекомендации по декомпозиции, потокам данных и управлению качеством.
Стефан Фрост выделяет несколько основополагающих принципов, которым должна следовать любая хорошо спроектированная архитектура данных: модульность (система должна быть декомпозирована на чётко разграниченные компоненты с определёнными зонами ответственности); масштабируемость (отдельные компоненты должны масштабироваться независимо друг от друга); воспроизводимость (эквивалентные входные данные должны давать эквивалентные или прозрачно детерминированные выходные данные); наблюдаемость (система должна генерировать достаточно сигналов для понимания своего внутреннего состояния без изучения исходного кода). Все четыре принципа имеют прямое операционное значение именно для систем аудита, поскольку аудит — итерационный процесс.
1.2. Уровни архитектурной абстракции
Критически важной дисциплиной при работе с эталонной архитектурой является ясность в отношении обсуждаемого уровня абстракции. Фрост выделяет три уровня, которые необходимо разграничивать: концептуальный (описывает бизнес-домены и потоки данных без привязки к конкретным технологиям); логический (определяет компоненты, их функции и интерфейсы взаимодействия); физический (задаёт конкретные технологии, форматы данных и инфраструктурные решения). «Смешение этих уровней — одна из наиболее распространённых ошибок при проектировании архитектур данных».
Для систем аудита это отображение выглядит следующим образом: концептуально задача состоит в сборе, оценке и представлении технических характеристик веб-сайта; логически это декомпозируется на службу обхода, службу анализа, хранилище результатов и движок отчётности; физически это может быть реализовано с помощью Playwright для рендеринга, Apache Kafka для очередей сообщений, ClickHouse для хранения агрегированных метрик и дашборда на React для отчётности. Эталонная архитектура работает преимущественно на концептуальном и логическом уровнях, оставляя физические решения командам реализации.
1.3. Четыре домена аудита и их взаимозависимость
Автоматический аудит веб-сайтов охватывает четыре основных домена качества, которые не являются независимыми.
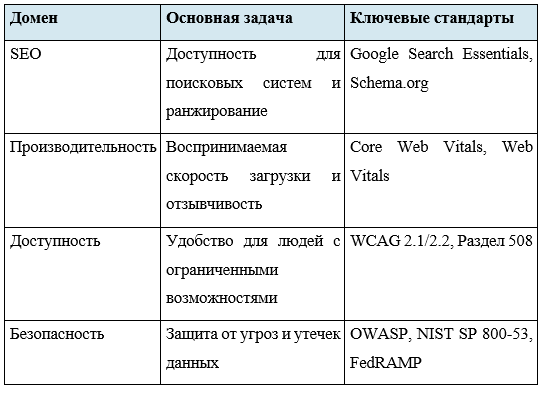
2. МИКРОСЕРВИСНАЯ АРХИТЕКТУРА ДЛЯ СИСТЕМ АУДИТА
2.1. Принцип единственной ответственности на уровне сервисов
Фрост особо подчёркивает, что эффективные архитектуры данных строятся на принципе единственной ответственности на уровне сервисов: каждый компонент решает ровно одну задачу и решает её хорошо. «Когда сервис пытается делать слишком много, он становится хрупким и трудно масштабируемым». Для систем аудита веб-сайтов этот принцип даёт естественную декомпозицию на пять основных сервисов.
Служба обхода (Crawler Service) отвечает исключительно за навигацию по URL-пространству целевого сайта, соблюдение политик обхода (robots.txt, crawl delay, ограничения глубины) и передачу сырых HTTP-ответов в конвейер обработки. Анализ на этом уровне не выполняется. Служба рендеринга (Renderer Service) обрабатывает страницы, зависящие от JavaScript, выполняя полный цикл рендеринга в среде безголового браузера и передавая результирующий снимок DOM нижестоящим компонентам. Служба анализа (Analyzer Service) получает HTML или DOM-представления, извлекает структурированные технические сигналы и генерирует структурированные записи метрик; она не имеет состояния между запросами. Служба сравнения (Comparator Service) сверяет текущие результаты аудита с историческими данными, формируя дельта-отчёты. Служба отчётности (Reporter Service) собирает итоговые отчёты в форматах, подходящих для различных аудиторий.
2.2. Избегание «распределённого монолита»
Фрост явно предостерегает от антипаттерна «распределённого монолита»: системы, формально декомпозированной на сервисы, но жёстко связанной синхронными вызовами и общими базами данных. «Если сбой одного сервиса парализует остальные — у вас нет микросервисов, у вас монолит с сетевыми вызовами». Для систем аудита этот антипаттерн особенно опасен, поскольку обход крупных сайтов — длительный процесс, потенциально занимающий часы или дни. Правильный паттерн — асинхронное взаимодействие через очередь сообщений: краулер помещает обработанные данные каждого URL в очередь по мере их поступления, а анализатор потребляет из очереди непрерывно и независимо.
2.3. Паттерны масштабирования
При управлении портфелем из десятков или сотен сайтов службы обхода и рендеринга становятся узкими местами по вычислительным ресурсам. Архитектурное решение состоит в горизонтальном масштабировании: для обходчиков применяется пул рабочих процессов с распределённой очередью задач; для рендереров — пул headless-браузеров (Chromium через Playwright или Puppeteer) с балансировкой нагрузки. Ключевой принцип: каждый рабочий процесс должен быть полностью изолированным и не должен разделять состояние с другими экземплярами. Для практической реализации характерно использование Kubernetes с Horizontal Pod Autoscaler для автоматического масштабирования на основе метрик глубины очереди.
3. КОНВЕЙЕРЫ ДАННЫХ
3.1. Режимы пакетной и потоковой обработки
Фрост описывает два фундаментальных паттерна конвейеров — пакетную и потоковую обработку — и утверждает, что зрелые архитектуры, как правило, применяют гибридный подход, сопоставляя режим обработки с требованиями к задержке и характеристиками данных. Для систем аудита это различие имеет прямое практическое значение. Пакетная обработка подходит для планируемых полных обходов сайта (еженедельных или ежемесячных комплексных аудитов), агрегации исторических данных для анализа трендов, формирования комплексных отчётов, требующих консолидации данных по всем страницам. Потоковая обработка необходима для мониторинга в реальном времени с оповещением о критических изменениях, инкрементальной индексации вновь обнаруженных URL и интеграции с CI/CD-конвейерами.
3.2. Четырёхуровневая структура конвейера
Канонический конвейер данных для систем аудита включает четыре уровня. Уровень 1 — Приём (Ingestion): URL-адреса поступают через планировщик; принцип Фроста — «уровень сбора должен быть тонким». Уровень 2 — Обработка (Processing): служба анализа потребляет сообщения из очереди; обработка должна быть идемпотентной. Уровень 3 — Хранение (Storage): результаты сохраняются в структурированном виде. Уровень 4 — Обслуживание (Serving): агрегированные данные передаются движку отчётности или раскрываются через API.
3.3. Управление качеством данных
Фрост особо акцентирует принцип: качество данных должно обеспечиваться на каждом этапе конвейера, а не только на выходе. «Мусор на входе — мусор на выходе, и никакой нижестоящий компонент не исправит фундаментально плохие данные». Для конвейеров аудита это означает реализацию контрольных точек валидации: после приёма — целостность HTTP-ответа и корректность кодировки; после обработки — валидация структурированных записей по схеме; перед сохранением — проверка на дубликаты и консистентность временны́х меток. Значительная доля URL в реальном обходе даст аномальные ответы (таймауты, некорректный HTML, блокировка ботов, петли редиректов), и конвейер должен обрабатывать их корректно.
4. АРХИТЕКТУРА ХРАНИЛИЩА
4.1. Трёхуровневая модель хранилища
Фрост описывает принцип многоуровневого хранилища как базовый паттерн для архитектур данных любого значимого масштаба: разные данные имеют разные профили доступа и жизненного цикла, и попытка хранить всё в едином хранилище ведёт либо к дороговизне, либо к медлительности, либо к обоим недостаткам. Для систем аудита этот принцип приводит к трёхуровневой модели.
Горячий уровень (Hot Layer) хранит результаты последнего аудита для каждого URL. Требования: низкая задержка чтения (менее 100 мс), высокая пропускная способность записи. Типичные реализации: Redis, DynamoDB или реляционные БД с агрессивным кешированием. Тёплый уровень (Warm Layer) хранит исторические результаты за период от 3 до 12 месяцев. Обслуживает аналитические запросы на сравнение трендов. Типичные реализации: колоночные хранилища (ClickHouse, BigQuery, Redshift). Холодный уровень (Cold Layer) хранит полные необработанные архивы обходов старше 12 месяцев. Типичные реализации: объектное хранилище (S3, Google Cloud Storage) с политиками жизненного цикла.
4.2. Разделение операционных и аналитических нагрузок
Системы аудита сталкиваются с фундаментальным различием двух типов рабочих нагрузок, которые не могут эффективно обслуживаться одним хранилищем. Операционные запросы (OLTP) предполагают быстрые операции с малой задержкой; критичны по времени для активного аудита и дашбордов. Аналитические запросы (OLAP) предполагают медленные сканирования, охватывающие миллионы записей; используются для анализа трендов и сегментации. Попытка обслуживать оба типа нагрузки из одной базы — классический антипаттерн, при котором аналитические запросы деградируют операционную задержку, а операционные записи конфликтуют с длительными аналитическими сканированиями.
5. ДВИЖКИ ПРАВИЛ: ПРОЕКТИРОВАНИЕ И ПРИМЕНЕНИЕ
5.1. Архитектура движка правил
Движок правил в контексте аудита веб-сайтов состоит из трёх фундаментальных уровней. Уровень сбора данных получает информацию о целевой странице: HTTP-запросы, загрузка ресурсов, построение DOM, анализ заголовков ответа сервера, выполнение JavaScript и измерение временны́х параметров. Уровень применения правил: каждое правило — это формализованное условие вида «если [условие X] → то [результат Y]». Правила могут быть бинарными (пройдено/не пройдено), например «наличие элемента <title>»; количественными (числовая оценка), например «LCP < 2,5 секунды»; или эвристическими (вероятностная оценка), например «текст ссылки достаточно описателен». Уровень агрегации и оценки собирает результаты отдельных правил в показатели уровня домена.
5.2. Категории правил SEO
Автоматический SEO-аудит охватывает несколько уровней технической проверки. Технический SEO включает корректность robots.txt и sitemap.xml; уникальность и наличие элементов <title> и <meta description>; корректность структуры URL-адресов (отсутствие сессионных параметров, избыточных редиректов); наличие canonical-тегов; корректность структурированных данных Schema.org; индексируемость страниц. Контентный SEO: проверка иерархии заголовков H1—H6; эвристики длины контента (страницы менее 300 слов могут помечаться как «тонкий контент»); анализ структуры внутренних ссылок; распределение анкорного текста. Оценка в SEO-инструментах использует модель взвешенной суммы с нормализацией по шкале
5.3. Метрики производительности и Lighthouse
Введение Google Core Web Vitals стандартизировало основные метрики для автоматического аудита производительности.
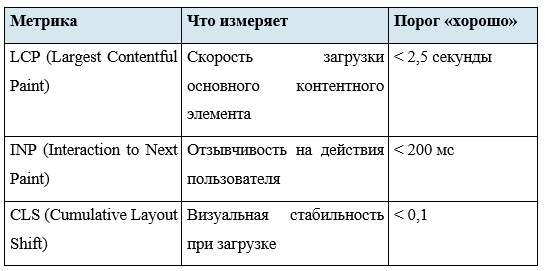
Google Lighthouse — наиболее значимая эталонная реализация многодоменного движка правил. Он выполняет сессию безголового браузера, загружает целевую страницу в условиях смоделированной сети, применяет сотни правил и формирует структурированный JSON-отчёт. Показатель производительности Lighthouse использует взвешенную модель: LCP — 25%, INP — 30%, CLS — 25%, First Contentful Paint — 10%, Speed Index — 10%. Каждое значение метрики переводится из сырого измерения в нормализованный балл через логистическую функцию, что делает шкалу нелинейной и должно учитываться при использовании оценок Lighthouse в качестве целевых показателей оптимизации.
5.4. Правила доступности и пределы автоматизации
Руководство по доступности веб-контента (WCAG) организовано вокруг четырёх свойств: воспринимаемость, управляемость, понятность и надёжность. Критическое архитектурное ограничение аудита доступности состоит в том, что автоматические инструменты могут надёжно обнаружить лишь около
6. АУДИТ БЕЗОПАСНОСТИ И FEDRAMP
6.1. FedRAMP Marketplace: структура и значение
FedRAMP Marketplace — официальный публичный реестр Федеральной программы управления рисками и авторизации, стандартизированного американского подхода к оценке безопасности и непрерывному мониторингу облачных продуктов для федеральных агентств. Маркетплейс перечисляет авторизованные продукты (получившие Authorization to Operate), продукты в процессе авторизации, а также аккредитованные сторонние организации по оценке (3PAO). FedRAMP Marketplace архитектурно значим как кейс-стади: список авторизованных сервисов — по существу, результат масштабного структурированного аудиторского процесса. FedRAMP трансформирует проверку безопасности из рекомендуемой практики в юридически обязательное условие работы для федеральных агентств.
6.2. NIST SP
FedRAMP основан на NIST SP
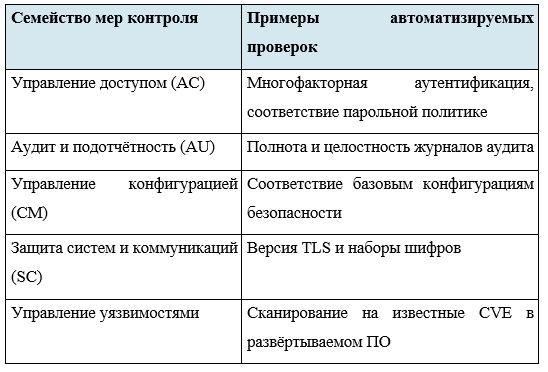
Ключевым операционным требованием FedRAMP является непрерывный мониторинг (ConMon): авторизованные провайдеры обязаны ежемесячно предоставлять результаты автоматического сканирования уязвимостей своему агентству-спонсору. Это требование институционализирует движок правил как обязательный операционный инструмент, а не опциональную меру улучшения качества.
6.3. Проверки безопасности веб-приложений
Для веб-приложений движок правил безопасности охватывает несколько категорий автоматических проверок. Проверки транспортного уровня: действительный TLS/SSL-сертификат; версия TLS 1.2 или выше; отсутствие смешанного контента. Проверки заголовков ответа безопасности: Content-Security-Policy (защита от XSS); Strict-Transport-Security (принудительное HTTPS); X-Frame-Options (защита от кликджекинга); X-Content-Type-Options: nosniff; Referrer-Policy; Permissions-Policy. Проверки конфигурации сервера: отсутствие листинга директорий; отсутствие чувствительных файлов (.env, .git, резервные архивы); корректная CORS-политика. Сканирование уязвимостей: обнаружение известных CVE в развёртываемых библиотеках; базовое автоматическое тестирование на SQL-инъекции и отражённый XSS.
6.4. Модели оценки безопасности
CVSS присваивает каждой уязвимости числовой показатель от 0 до 10. Однако агрегация оценок CVSS не может быть просто усреднена. Модель FedRAMP отражает правильный принцип: наличие любой неустранённой критической находки (CVSS 7.0+) является основанием для приостановки авторизации независимо от средней оценки. Это отражает фундаментальную асимметрию риска безопасности: одна критическая уязвимость не может быть компенсирована множеством хорошо настроенных мер контроля. Движки правил для аудита безопасности должны реализовывать эту пороговую логику явно, а не полагаться на усреднённую агрегацию оценок.
7. РЕАЛИЗАЦИИ НА ОСНОВЕ ОТКРЫТОГО ПО И CI/CD
7.1. Инструменты с открытым исходным кодом
Экосистема открытого ПО вокруг аудита веб-сайтов предоставляет практические эталонные реализации архитектурных паттернов. Google Lighthouse — канонический многодоменный движок правил, предоставляющий производственные реализации проверок производительности, доступности, лучших практик и SEO. Доступность исходного кода позволяет командам инспектировать логику правил, понимать взвешенную модель оценки и адаптировать набор правил. Lighthouse CI расширяет базовый инструмент оркестрацией для непрерывной интеграции. Pa11y — специализированный инструмент тестирования доступности на основе движка Axe, разработанный для автоматизации с
7.2. Паттерны интеграции с CI/CD
Интеграция инструментов аудита в CI/CD-конвейеры трансформирует аудит из периодической ручной деятельности в непрерывный автоматизированный контроль процесса деплоя. Предеплойный аудит запускается против тестовой среды; находки выше настроенных порогов блокируют деплой. Постдеплойная верификация запускается против производственной среды сразу после деплоя; отклонения инициируют автоматический откат или эскалацию оповещений. Запланированный непрерывный мониторинг выполняется по регулярному расписанию (ежедневно для критических страниц, еженедельно для полного обхода). Архитектурное требование к CI/CD-интеграции: инструменты должны производить машиночитаемые структурированные выходные данные (как правило, JSON) и поддерживать неинтерактивное выполнение с настраиваемыми кодами завершения.
7.3. Elasticsearch и Grafana для хранения и визуализации
В масштабе интегрированные в CI/CD системы аудита генерируют значительные объёмы структурированных данных. Elasticsearch обеспечивает полнотекстовый поиск и агрегацию по структурированным записям, позволяя выполнять запросы вида: «покажи все страницы, где LCP ухудшился более чем на 20% между двумя последними сессиями аудита» или «перечисли все URL, где отсутствует заголовок CSP, упорядоченные по расчётному органическому трафику». Grafana подключается к Elasticsearch для визуализации временны́х рядов, позволяя командам отслеживать эволюцию показателей качества и выявлять регрессии. Комбинация создаёт стек наблюдаемости аудита, удовлетворяющий принципу Фроста.
8. АРХИТЕКТУРА ОТЧЁТНОСТИ И ПРОБЛЕМА «ПОСЛЕДНЕЙ МИЛИ»
8.1. Проектирование слоя обслуживания
Фрост описывает слой обслуживания как специализированный компонент, цель которого — подготовить данные в формах, оптимизированных для конкретных потребителей, а не предоставлять сырые представления хранилища. Это архитектурно значимо, поскольку потребители результатов аудита качественно различаются. SEO-специалистам нужны: сводный дашборд с категоризированными проблемами; возможность детализации от сайта до страницы; графики трендов; экспорт в форматах клиентской отчётности. Командам разработчиков нужны: детальные технические отчёты; diff-отчёты о изменениях; JSON API для CI/CD. Руководителям нужны: агрегированные показатели здоровья; индикаторы трендов; PDF-экспорт.
8.2. Данные как продукт
Фрост вводит концепцию «данных как продукта»: каждый выходной артефакт архитектуры должен рассматриваться как продукт с определённым владением, соглашениями об уровне качества, документацией и механизмами обратной связи. Применительно к отчётам это означает: каждый тип отчёта имеет спецификацию; отчёты версионированы; отчёты содержат информацию о происхождении данных (временны́е метки сбора, процент охвата обходом, ошибки при сборе).
8.3. Проблема «последней мили»
«Самый точный анализ бесполезен, если он не достигает лиц, принимающих решения, в форме, пригодной для действий». Фрост называет это «проблемой последней мили» данных. Технический директор, видящий необработанные метрики без контекста о бизнес-воздействии, не может эффективно распределять ресурсы. SEO-специалист, получающий JSON-файл без визуализации приоритетов, тратит время на ручное ранжирование. Архитектурное следствие: конкретные форматы вывода для каждой аудитории должны быть first-class требованиями, а не запоздалыми добавлениями.
9. ИНТЕГРИРОВАННАЯ МОДЕЛЬ ОЦЕНКИ
9.1. Проблема агрегации
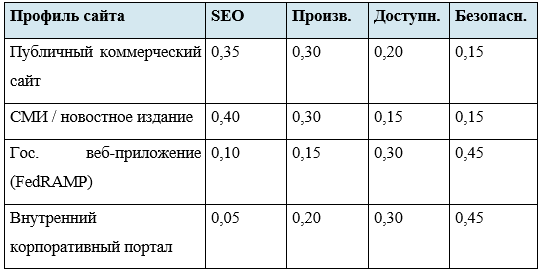
Практическая проблема разработчиков комплексных аудиторских платформ — как объединить оценки из четырёх структурно несовместимых доменов в осмысленный интегральный показатель. Трудности: несовместимые шкалы (оценка SEO 85/100 и отсутствие заголовка HSTS нельзя напрямую суммировать); различные характеристики ошибок (проблема производительности постепенно ухудшает UX; уязвимость безопасности открывает возможность немедленного взлома); ситуационная значимость (для новостного издания вес SEO должен быть высоким; для госприложения в FedRAMP-контексте должна доминировать безопасность).
9.2. Взвешенная оценка и пороговые модели
Наиболее распространённый подход — контекстно-зависимая взвешенная сумма: Итоговая оценка = w1*SEO + w2*Производительность + w3*Доступность + w4*Безопасность, где сумма весов равна 1,0.
Альтернативная модель — пороговая (gate model): до взвешенной агрегации должны быть соблюдены обязательные минимальные пороги. Если оценка безопасности ниже 60 — общий результат «Не пройдено» независимо от прочих доменов; если оценка доступности не соответствует законодательному минимуму — «Требует немедленного устранения». Эта структура напрямую согласована с моделью авторизации FedRAMP, где одна неустранённая критическая уязвимость является основанием для приостановки авторизации независимо от общего уровня качества системы.
10. ЧИСЛЕННЫЙ КЕЙС-СТАДИ: ЭКОНОМИКА АВТОМАТИЗИРОВАННОГО АУДИТА
10.1. Описание сценария
Для практического обоснования рассмотрим следующий сценарий: цифровое агентство управляет 45 клиентскими веб-сайтами, каждый из которых содержит в среднем 800 проиндексированных страниц. Текущая практика — ежеквартальные ручные технические аудиты, проводимые старшим SEO- и техническим аналитиком. Параметры ручного аудита: страниц на сайт — 800; сайтов — 45; всего страниц в портфеле — 36 000; время проверки одной страницы — 4 минуты; общее время за квартал — 36 000 × 4 мин = 144 000 мин = 2 400 часов; стоимость аналитика — 85 $/час; квартальные трудозатраты — 2 400 × 85 $ = 204 000 $; годовые трудозатраты на ручной аудит — 816 000 $. Этот расчёт не учитывает альтернативные издержки времени аналитика.
10.2. Параметры автоматизированной системы
Агентство инвестирует в создание платформы на основе описанной эталонной архитектуры. Инфраструктурные расходы (ежемесячно): вычислительные ресурсы служб обхода и рендеринга — 1 200 $; очередь сообщений (управляемый Kafka) — 400 $; аналитическое хранилище (ClickHouse или BigQuery) — 600 $; объектное хранилище (S3-эквивалент) — 180 $; мониторинг и наблюдаемость — 200 $. Итого ежемесячно — 2 580 $; годовые инфраструктурные расходы — 30 960 $. Разработка (единовременно): начальная разработка платформы (6 месяцев, 2 инженера по 130 000 $/год) — 130 000 $; амортизация за 3 года — 43 333 $/год. Операционные расходы: поддержка (0,25 DevOps) — 27 500 $/год. Итого годовые расходы автоматизированной системы: 30 960 + 43 333 + 27 500 = 101 793 $.
10.3. Сравнительный анализ и ROI
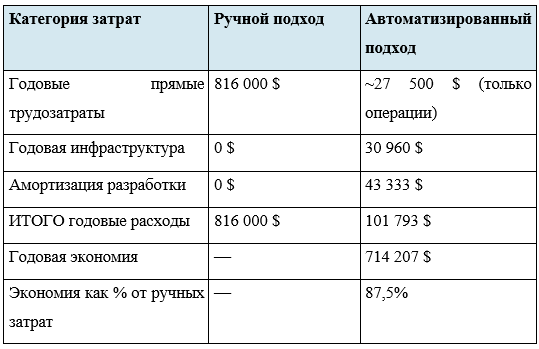
Помимо экономии затрат, автоматизированная система обеспечивает качественные улучшения. Частота аудита: ручные аудиты — ежеквартально; автоматизированные — ежедневно, что даёт в 90 раз более частый мониторинг. Охват: автоматизированный обход — 100% проиндексированных страниц против выборки при ручной проверке. Задержка обнаружения: критическая проблема (ошибка 500, потеря SSL) обнаруживается в течение 24 часов против до 90 дней при квартальном ручном аудите. Исторический анализ: накопление структурированных данных для анализа трендов.
10.4. Анализ безубыточности
При указанных параметрах точка безубыточности достигается в первый год: разработка (130 000 $) + 12 мес. инфраструктуры (30 960 $) + 12 мес. операций (27 500 $) = 188 460 $ — общие расходы первого года. Чистая экономия первого года: 816 000 $ − 188 460 $ = 627 540 $. Даже при консервативном сценарии — платформа готова через 9 месяцев, бюджет разработки превышен на 50% (195 000 $) — безубыточность достигается до конца первого полного года эксплуатации. Полученные данные подтверждают, что автоматизация технического аудита обеспечивает убедительную финансовую отдачу при любом портфеле более
11. НАБЛЮДАЕМОСТЬ И ОПЕРАЦИОННАЯ НАДЁЖНОСТЬ
11.1. Три столпа наблюдаемости
Настоянчивость Фроста на наблюдаемости как архитектурном принципе — «Если вы не можете ответить на вопрос „что происходит в системе прямо сейчас?“ без просмотра кода — архитектура не готова к производству» — воплощается в трёх операционных возможностях для систем аудита. Метрики: глубина очереди (URL-адреса, ожидающие обработки), пропускная способность обхода (URL/сек.), частота ошибок по сервисам, сквозная задержка конвейера (от подачи URL до доступности результата). Журналы: структурированные записи для каждого события конвейера, включая идентификатор сессии, URL, временну́ю метку и статус обработки. Журналы ошибок должны классифицировать сбои по типу (таймаут сети, HTTP 4xx/5xx, ошибка рендеринга JS, ошибка валидации схемы). Трассировки: распределённая трассировка от поступления URL в очередь через каждый этап до итогового сохранения.
11.2. Управление ошибками: очереди «мёртвых писем»
Паттерн очереди «мёртвых писем» (DLQ) — обязательный элемент надёжных конвейеров. Для систем аудита URL-адреса, обработка которых не удалась, должны следовать протоколу: повторная попытка с экспоненциальной задержкой (1 минута, 5 минут, 30 минут); после N неудачных попыток (обычно
11.3. Дополнительные механизмы операционной устойчивости
Производственные системы аудита требуют реализации дополнительных механизмов. Circuit Breaker (предохранитель) предотвращает каскадные сбои: если целевой сайт возвращает ошибки на более чем 50% запросов в определённом временном окне, дальнейшие запросы к нему временно прекращаются, сберегая ресурсы для доступных сайтов. Rate Limiting (ограничение скорости) обеспечивает уважение к политикам целевых сайтов: систематическое соблюдение директивы Crawl-delay и адаптация частоты запросов на основе времени ответа предотвращают непреднамеренную нагрузку и блокировку. Graceful Degradation (мягкая деградация): при недоступности отдельных компонентов (например, службы рендеринга) система должна продолжать аудит статических страниц, фиксируя ограниченность результатов в отчёте.
ЗАКЛЮЧЕНИЕ И РЕКОМЕНДАЦИИ
Основные выводы
Эталонная архитектура обеспечивает существенную операционную ценность. Инвестиции в общую архитектурную модель дают конкретные результаты: согласованность команды, снижение затрат на онбординг, более высокое качество решений при масштабировании. «Хорошая эталонная архитектура данных — та, которую можно понять, объяснить и воспроизвести». Декомпозиция на микросервисы оправдана при подлинном соблюдении принципа единственной ответственности — разделение обхода, рендеринга, анализа, сравнения и отчётности позволяет независимо масштабировать каждый компонент. Критическое условие — асинхронная коммуникация через очереди сообщений. Гибридная архитектура конвейера (пакетная + потоковая) оптимально соответствует требованиям аудита. Многоуровневое хранилище экономически необходимо при масштабе от 36 000 URL-записей за цикл. FedRAMP формализует обязательные требования к аудиту безопасности, переводя его из рекомендуемой практики в юридическое обязательство. Модели оценки должны быть контекстно-чувствительными и иметь пороговую структуру для доменов безопасности и доступности. Экономика автоматизации убедительна: снижение затрат на 87,5% при
Рекомендации для дальнейших исследований
Перспективными направлениями являются: (1) эмпирическая калибровка взвешенных моделей оценки через корреляцию конфигураций весов с бизнес-результатами; (2) исследование правовых и этических границ аудиторского сканирования в условиях развитых антибот-систем; (3) разработка методологий тестирования самих систем аудита, включая регрессионное тестирование при обновлении правил; (4) изучение взаимодействия требований FedRAMP и Раздела 508 на уровне конкретного инструментария; (5) формализация «непрерывного SEO» как DevOps-дисциплины с моделями зрелости, паттернами реализации и метриками успеха для организаций на разных стадиях автоматизации.
СПИСОК ЛИТЕРАТУРЫ
1. Frost S. Creating a Reference Data Architecture. Medium. URL: https://frost-stefan.medium.com/creating-a-reference-data-architecture-5c2346976c6f (дата обращения: 15.01.2025).
2. FedRAMP Marketplace. Federal Risk and Authorization Management Program. U.S. General Services Administration. URL: https://marketplace.fedramp.gov/ (дата обращения: 15.01.2025).
3. Bezdek V. Awesome GitHub Projects. GitHub Repository. URL: https://github.com/viktorbezdek/awesome-github-projects (дата обращения: 15.01.2025).
4. Google. Web.dev: Core Web Vitals. URL: https://web.dev/vitals/ (дата обращения: 15.01.2025).
5. W3C. Web Content Accessibility Guidelines (WCAG) 2.2. URL: https://www.w3.org/TR/WCAG22/ (дата обращения: 15.01.2025).
6. NIST. Special Publication
7. OWASP. OWASP Top Ten. URL: https://owasp.org/www-project-top-ten/ (дата обращения: 15.01.2025).
8. Google. Lighthouse: Automated auditing, performance metrics, and best practices for the web. URL: https://developers.google.com/web/tools/lighthouse (дата обращения: 15.01.2025).
9. Pa11y. Pa11y: Your automated accessibility testing pal. URL: https://pa11y.org (дата обращения: 15.01.2025).
10. OWASP. OWASP ZAP (Zed Attack Proxy). URL: https://www.zaproxy.org (дата обращения: 15.01.2025).
11. Apache Software Foundation. Apache Kafka: Distributed event streaming platform. URL: https://kafka.apache.org (дата обращения: 15.01.2025).
12. ClickHouse Inc. ClickHouse: Fast open-source column-oriented database management system. URL: https://clickhouse.com (дата обращения: 15.01.2025).
13. FIRST.org. Common Vulnerability Scoring System (CVSS) Version 3.1 Specification Document. URL: https://www.first.org/cvss/v3.1/specification-document (дата обращения: 15.01.2025).
14. Grafana Labs. Grafana: The open and composable observability and data visualization platform. URL: https://grafana.com (дата обращения: 15.01.2025).
15. Elastic. Elasticsearch: The distributed search and analytics engine. URL: https://www.elastic.co/elasticsearch (дата обращения: 15.01.2025).
16. Kubernetes Authors. Kubernetes: Production-Grade Container Orchestration. URL: https://kubernetes.io (дата обращения: 15.01.2025).
17. Schema.org Community. Schema.org: A shared vocabulary for structured data on the internet. URL: https://schema.org (дата обращения: 15.01.2025).






