–љ–∞—Г—З–љ—Л–є
–ґ—Г—А–љ–∞–ї
–°—А–Њ—З–љ–∞—П –њ—Г–±–ї–Є–Ї–∞—Ж–Є—П –љ–∞—Г—З–љ–Њ–є —Б—В–∞—В—М–Є
+7 995 770 98 40
+7 995 202 54 42
info@journalpro.ru

–Р–ї–≥–Њ—А–Є—В–Љ –≥–µ–љ–µ—А–∞—Ж–Є–Є –Љ–µ—В–∞—В–µ–≥–Њ–≤ –і–ї—П –њ–Њ–Є—Б–Ї–Њ–≤–Њ–≥–Њ –њ—А–Њ–і–≤–Є–ґ–µ–љ–Є—П —Б–∞–є—В–∞

–†—Г–±—А–Є–Ї–∞: –≠–Ї–Њ–љ–Њ–Љ–Є—З–µ—Б–Ї–Є–µ –љ–∞—Г–Ї–Є
–Ц—Г—А–љ–∞–ї: «–Х–≤—А–∞–Ј–Є–є—Б–Ї–Є–є –Э–∞—Г—З–љ—Л–є –Ц—Г—А–љ–∞–ї вДЦ12 2018» (–і–µ–Ї–∞–±—А—М, 2018)
–Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ—А–Њ—Б–Љ–Њ—В—А–Њ–≤ —Б—В–∞—В—М–Є: 1863
–Я–Њ–Ї–∞–Ј–∞—В—М PDF –≤–µ—А—Б–Є—О –Р–ї–≥–Њ—А–Є—В–Љ –≥–µ–љ–µ—А–∞—Ж–Є–Є –Љ–µ—В–∞—В–µ–≥–Њ–≤ –і–ї—П –њ–Њ–Є—Б–Ї–Њ–≤–Њ–≥–Њ –њ—А–Њ–і–≤–Є–ґ–µ–љ–Є—П —Б–∞–є—В–∞
–Р–њ—Г—Е—В–Є–љ –Ф–Љ–Є—В—А–Є–є –Ш–≥–Њ—А–µ–≤–Є—З,
–Ю–Ю–Ю ¬Ђ–Ш–љ—Б—В—А—Г–Љ–µ–љ—В—Л –≥–µ–љ–µ—А–∞—Ж–Є–Є –і–Њ—Е–Њ–і–∞¬ї
–У–µ–љ–µ—А–∞—Ж–Є—П –Љ–µ—В–∞—В–µ–≥–Њ–≤ вАФ —Н—В–Њ –Ј–∞–і–∞—З–∞, –Ї–Њ—В–Њ—А–Њ–є –Ј–∞–љ–Є–Љ–∞—О—В—Б—П –≤—Б–µ SEO-—Б–њ–µ—Ж–Є–∞–ї–Є—Б—В—Л –і–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –њ—А–Њ–µ–Ї—В–∞.
–Э–∞–њ–Є—Б–∞–љ–Є–µ —В–µ–Ї—Б—В–Њ–≤ title –Є description –і–ї—П –Њ–і–љ–Њ–≥–Њ –њ—А–Њ–µ–Ї—В–∞ –Њ—В–љ–Є–Љ–∞–µ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ —З–∞—Б–Њ–≤ –≤—А–µ–Љ–µ–љ–Є —Б–њ–µ—Ж–Є–∞–ї–Є—Б—В–∞. –І—В–Њ–±—Л –≤—Л–і–µ–ї–Є—В—М –≤—А–µ–Љ—П –љ–∞ –±–Њ–ї–µ–µ –Є–љ—В–µ–ї–ї–µ–Ї—В—Г–∞–ї—М–љ—Л–µ –Ј–∞–і–∞—З–Є, —А–µ—И–Є–ї–Є –∞–≤—В–Њ–Љ–∞—В–Є–Ј–Є—А–Њ–≤–∞—В—М –њ—А–Њ—Ж–µ—Б—Б –љ–∞–њ–Є—Б–∞–љ–Є—П –Љ–µ—В–∞—В–µ–≥–Њ–≤.
–Э—Г–ґ–љ–Њ –Њ—В–Љ–µ—В–Є—В—М, —З—В–Њ –Љ–µ—В–∞—В–µ–≥–Є –њ–Њ–і–±–Є—А–∞—О—В—Б—П –љ–∞ –Ї–∞–ґ–і—Г—О —Б—В—А–∞–љ–Є—Ж—Г. –Я—А–Є —Н—В–Њ–Љ –љ–∞ –Њ–і–љ—Г —Б—В—А–∞–љ–Є—Ж—Г –Љ–Њ–≥—Г—В –≤–µ—Б—В–Є —Б—А–∞–Ј—Г –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –њ–Њ–Є—Б–Ї–Њ–≤—Л—Е –Ј–∞–њ—А–Њ—Б–Њ–≤, –Є—Е –≤—Б–µ –љ—Г–ґ–љ–Њ —Г—З–Є—В—Л–≤–∞—В—М –њ—А–Є –њ–Њ–і–±–Њ—А–µ –Љ–µ—В–∞—В–µ–≥–Њ–≤.
–Я–µ—А–≤–Є—З–љ—Л–є –∞–љ–∞–ї–Є–Ј
–Э–∞ –њ–µ—А–≤–Њ–Љ —Н—В–∞–њ–µ –±—Л–ї –њ—А–Њ–≤–µ–і–µ–љ –∞–љ–∞–ї–Є–Ј –њ–Њ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П–Љ, –Ї–Њ—В–Њ—А—Л–µ –љ–∞–Ї–ї–∞–і—Л–≤–∞—О—В—Б—П –љ–∞ title –Є description. –Т –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М вАФ —Н—В–Њ –і–ї–Є–љ–∞ –Є –і–Њ–њ—Г—Б—В–Є–Љ—Л–µ —Б–Є–Љ–≤–Њ–ї—Л.
–Ф–ї—П —Н—В–Њ–≥–Њ –њ—А–Њ–≤–µ–ї–Є –Ї–Њ–љ—Б—Г–ї—М—В–∞—Ж–Є—О —Б –љ–∞—И–Є–Љ–Є —Н–Ї—Б–њ–µ—А—В–∞–Љ–Є, –∞ —В–∞–Ї–ґ–µ –њ—А–Њ–≤–µ—А–Є–ї–Є –Љ–µ—В–∞—В–µ–≥–Є, –Ї–Њ—В–Њ—А—Л–µ —Б–њ–µ—Ж–Є–∞–ї–Є—Б—В—Л –њ–Є—И—Г—В –≤—А—Г—З–љ—Г—О.
–Ф–ї—П title –≤—Л–і–µ–ї–Є–ї–Є —А–∞–Ј—А–µ—И–µ–љ–љ—Л–є —Б–њ–Є—Б–Њ–Ї –Ј–љ–∞–Ї–Њ–≤ –њ—А–µ–њ–Є–љ–∞–љ–Є—П, –∞ —В–∞–Ї–ґ–µ –љ–∞–ї–Њ–ґ–Є–ї–Є –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П –љ–∞ –њ–µ—А–µ—Б–њ–∞–Љ.
–Ф–ї—П description —Г—Б—В–∞–љ–Њ–≤–Є–ї–Є –≥—А–∞–љ–Є—Ж—Л –Њ—В 100 –і–Њ 300 —Б–Є–Љ–≤–Њ–ї–Њ–≤. –Ч–љ–∞–Ї–Є –њ—Г–љ–Ї—В—Г–∞—Ж–Є–Є –і–Њ–њ—Г—Б–Ї–∞—О—В—Б—П.
–У–µ–љ–µ—А–∞—Ж–Є—П title
–Ш—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е —В—Л—Б—П—З title –≤ –≤—Л–і–∞—З–µ –њ–Њ –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Є–Љ –Ј–∞–њ—А–Њ—Б–∞–Љ –њ–Њ–Ї–∞–Ј–∞–ї–Њ, —З—В–Њ –±–Њ–ї–µ–µ 50% —Б—В—А–∞–љ–Є—Ж –≤ title —Б–Њ–і–µ—А–ґ–∞—В –љ–∞–Ј–≤–∞–љ–Є–µ –Ї–Њ–Љ–њ–∞–љ–Є–Є –Є –Њ–±—Л—З–љ–Њ –Њ–љ–Њ —Г–Ї–∞–Ј—Л–≤–∞–µ—В—Б—П –≤ –Ї–Њ–љ—Ж–µ title.
–Т —Б–≤—П–Ј–Є —Б —Н—В–Є–Љ –≤ –∞–ї–≥–Њ—А–Є—В–Љ –±—Л–ї –≤—Б—В—А–Њ–µ–љ –њ–Њ–Є—Б–Ї –љ–∞–Ј–≤–∞–љ–Є—П –Ї–Њ–Љ–њ–∞–љ–Є–Є/–Љ–∞–≥–∞–Ј–Є–љ–∞ –љ–∞ —Б–∞–є—В–µ –њ–Њ –Њ–њ—А–µ–і–µ–ї–µ–љ–љ—Л–Љ —И–∞–±–ї–Њ–љ–∞–Љ.
–Э–∞–њ—А–Є–Љ–µ—А:
¬Ј –Т –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–С–Њ–і—А—Л–є —А–Њ—Б—В–Њ–≤—Й–Є–Ї¬ї
¬Ј –Ш–љ—В–µ—А–љ–µ—В-–Љ–∞–≥–∞–Ј–Є–љ ¬Ђ–Ч–Њ–ї–Њ—В–Њ–є –њ–ї–∞—Д–Њ–љ¬ї
–Р–љ–∞–ї–Є–Ј title –≤ –≤—Л–і–∞—З–µ –Є title, –Ї–Њ—В–Њ—А—Л–µ –њ–Є—И—Г—В –љ–∞—И–Є —Б–њ–µ—Ж—Л –њ–Њ–Ї–∞–Ј–∞–ї, —З—В–Њ title —Б–Њ–і–µ—А–ґ–∞—В –Ј–∞–њ—А–Њ—Б—Л, –њ–Њ –Ї–Њ—В–Њ—А—Л–Љ –Є–і–µ—В –њ—А–Њ–і–≤–Є–ґ–µ–љ–Є–µ, –љ–Њ –Њ–±—Л—З–љ–Њ —Н—В–Њ –љ–µ –њ–Њ–ї–љ–∞—П —Д–Њ—А–Љ–∞. –Ґ–∞–Ї–ґ–µ —З–∞—Б—В–Њ –Є–≥–љ–Њ—А–Є—А—Г—О—В—Б—П –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Є–µ –Љ–∞—А–Ї–µ—А—Л: —Ж–µ–љ–∞, –Ї—Г–њ–Є—В—М. –Я–Њ—Н—В–Њ–Љ—Г –≤ –Њ—Б–љ–Њ–≤—Г –∞–ї–≥–Њ—А–Є—В–Љ–∞ –≥–µ–љ–µ—А–∞—Ж–Є–Є title –ї–µ–≥ –њ–Њ–Є—Б–Ї –Ї–∞–љ–і–Є–і–∞—В–Њ–≤ –≤ title, –∞ –Ј–∞—В–µ–Љ –≤—Л–±–Њ—А –Ї–∞–љ–і–Є–і–∞—В–∞ —Б –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ—Л–Љ –њ–Њ–Ї—А—Л—В–Є–µ–Љ –≤—Б–µ—Е –Ј–∞–њ—А–Њ—Б–Њ–≤, –љ–Њ —Б —Г—З–µ—В–Њ–Љ —Д–Є–ї—М—В—А–Њ–≤.
–Т –Ї–∞—З–µ—Б—В–≤–µ –Ї–∞–љ–і–Є–і–∞—В–Њ–≤ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В—Б—П title —Б—В—А–∞–љ–Є—Ж –Ї–Њ–љ–Ї—Г—А–µ–љ—В–Њ–≤, –љ–∞—И —Д–∞–Ї—В–Є—З–µ—Б–Ї–Є–є title (–µ—Б–ї–Є –µ—Б—В—М), –љ–∞—И–Є –Ј–∞–≥–Њ–ї–Њ–≤–Ї–Є –љ–∞ —Б—В—А–∞–љ–Є—Ж–µ (–њ–Њ —В–µ–≥—Г h1). –Ъ–∞–ґ–і—Л–є –Ї–∞–љ–і–Є–і–∞—В –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ–Њ —А–∞–Ј–±–Є–≤–∞–µ—В—Б—П –љ–∞ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П, –µ—Б–ї–Є —Н—В–Њ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ. –Х—Б–ї–Є —Б—А–µ–і–Є –Ј–∞–њ—А–Њ—Б–Њ–≤ –µ—Б—В—М 2 –Ј–∞–њ—А–Њ—Б–∞, –Ї–Њ—В–Њ—А—Л–µ –љ–µ –њ–µ—А–µ—Б–µ–Ї–∞—О—В—Б—П –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є –њ–Њ –љ–Њ—А–Љ–∞–ї–Є–Ј–Њ–≤–∞–љ–љ—Л–Љ —Б–ї–Њ–≤–∞–Љ, —В–Њ –≤ –Ї–∞—З–µ—Б—В–≤–µ –Ї–∞–љ–і–Є–і–∞—В–∞ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –Є—Е –Њ–±—К–µ–і–Є–љ–µ–љ–Є–µ —З–µ—А–µ–Ј –Ј–∞–њ—П—В—Г—О. –Ґ–∞–Ї–ґ–µ –≤—Б–µ –Ј–∞–њ—А–Њ—Б—Л –і–Њ–±–∞–≤–ї—П—О—В—Б—П –≤ –Ї–∞–љ–і–Є–і–∞—В—Л.
–Т—Б–µ –Ї–∞–љ–і–Є–і–∞—В—Л –њ—А–Њ—Е–Њ–і—П—В —Д–Є–ї—М—В—А–∞—Ж–Є—О. –Т –Ї–∞—З–µ—Б—В–≤–µ –Њ–і–љ–Њ–≥–Њ –Є–Ј —Д–Є–ї—М—В—А–Њ–≤ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –њ—А–Њ–≤–µ—А–Ї–∞, —З—В–Њ –≤—Б–µ —Б–ї–Њ–≤–∞ –Ї–∞–љ–і–Є–і–∞—В–∞ –µ—Б—В—М –љ–∞ –њ—А–Њ–і–≤–Є–≥–∞–µ–Љ–Њ–є —Б—В—А–∞–љ–Є—Ж–µ. –°–і–µ–ї–∞–љ–Њ —Н—В–Њ, —З—В–Њ–±—Л –љ–µ –≤—Л–±—А–∞—В—М –љ–µ—А–µ–ї–µ–≤–∞–љ—В–љ–Њ–≥–Њ –Ї–∞–љ–і–Є–і–∞—В–∞ –Є–ї–Є –Ї–∞–љ–і–Є–і–∞—В–∞, –≤ –Ї–Њ—В–Њ—А–Њ–Љ –µ—Б—В—М, –љ–∞–њ—А–Є–Љ–µ—А, –љ–∞–Ј–≤–∞–љ–Є–µ –љ–∞—И–µ–≥–Њ –Ї–Њ–љ–Ї—Г—А–µ–љ—В–∞.
–Ф—А—Г–≥–Є–Љ —Д–Є–ї—М—В—А–Њ–Љ —П–≤–ї—П–µ—В—Б—П –њ—А–Њ–≤–µ—А–Ї–∞ –љ–∞ –њ–µ—А–µ—Б–њ–∞–Љ. –Ф–ї—П —Н—В–Њ–≥–Њ –≤—Л—А–∞–±–Њ—В–∞–ї–Є –њ—А–∞–≤–Є–ї–∞, –њ–Њ –Ї–Њ—В–Њ—А—Л–Љ –Њ–њ—А–µ–і–µ–ї—П–ї–Є —П–≤–ї—П–µ—В—Б—П –ї–Є title –њ–µ—А–µ—Б–њ–∞–Љ–ї–µ–љ–љ—Л–Љ –Є–ї–Є –љ–µ—В.
–°—З–Є—В–∞–µ–Љ title –њ–µ—А–µ—Б–њ–∞–Љ–ї–µ–љ–љ—Л–Љ, –µ—Б–ї–Є:
1. –Ю–і–љ–Њ —Б–ї–Њ–≤–Њ –њ–Њ–≤—В–Њ—А—П–µ—В—Б—П 3 –Є –±–Њ–ї–µ–µ —А–∞–Ј.
¬Ђ–Ъ—Г–њ–Є—В—М –Њ–Ї–љ–∞¬ї, ¬Ђ–њ–ї–∞—Б—В–Є–Ї–Њ–≤—Л–µ –Њ–Ї–љ–∞ –љ–µ–і–Њ—А–Њ–≥–Њ¬ї, ¬Ђ—Ж–µ–љ—Л –љ–∞ –Њ–Ї–љ–∞¬ї
2. –Х—Б—В—М 3 –Є –±–Њ–ї–µ–µ —Б–ї–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ –≤ title –≤—Б—В—А–µ—З–∞—О—В—Б—П –±–Њ–ї–µ–µ 1 —А–∞–Ј–∞.
¬Ђ–¶–µ–љ–∞ –љ–∞ —Г–Ј–Є –њ–Њ—З–µ–Ї –Љ–Њ—Б–Ї–≤–∞¬ї, ¬Ђ—Г–Ј–Є –Љ–Њ—З–µ–≤–Њ–≥–Њ –њ—Г–Ј—Л—А—П –Є –њ–Њ—З–µ–Ї –≤ –Љ–Њ—Б–Ї–≤–µ¬ї
3. –Х—Б—В—М –±–Є–≥—А–∞–Љ–Љ–∞, –Ї–Њ—В–Њ—А–∞—П –≤—Б—В—А–µ—З–∞–µ—В—Б—П –±–Њ–ї—М—И–µ 1 —А–∞–Ј–∞.
¬Ђ–Ч–∞–њ—З–∞—Б—В–Є –®–µ–≤—А–Њ–ї–µ вАФ –Ї–∞—В–∞–ї–Њ–≥, —Ж–µ–љ—Л¬ї, ¬Ђ–Ї—Г–њ–Є—В—М –Ј–∞–њ—З–∞—Б—В–Є –®–µ–≤—А–Њ–ї–µ –≤ –Ь–Њ—Б–Ї–≤–µ¬ї
–Я–Њ—Б–ї–µ —Д–Є–ї—М—В—А–∞—Ж–Є–Є –≤—Б–µ –Њ—Б—В–∞–≤—И–Є–µ—Б—П –Ї–∞–љ–і–Є–і–∞—В—Л —А–∞–љ–ґ–Є—А—Г—О—В—Б—П –њ–Њ –њ–Њ–Ї—А—Л—В–Є—О. –Ф–ї—П —А–∞—Б—З–µ—В–∞ –њ–Њ–Ї—А—Л—В–Є—П –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Є—Б—М —В—А–Є–≥—А–∞–Љ–Љ—Л. –Ґ—А–Є–≥—А–∞–Љ–Љ–∞ вАФ —Н—В–Њ –љ–∞–±–Њ—А 3 —Б–Є–Љ–≤–Њ–ї–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ –Љ—Л –њ–Њ–ї—Г—З–∞–µ–Љ —Б–Ї–Њ–ї—М–Ј—П—Й–Є–Љ –Њ–Ї–љ–Њ–Љ –њ–Њ –Ј–∞–њ—А–Њ—Б—Г –Є–ї–Є –Ї–∞–љ–і–Є–і–∞—В—Г —Б —И–∞–≥–Њ–Љ –Њ–і–Є–љ. –Ґ.–µ. –і–ї—П –Ј–∞–њ—А–Њ—Б–∞ ¬Ђ–Ї—Г–њ–Є—В—М –і–µ—В—Б–Ї–Є–µ —Б–∞–њ–Њ–≥–Є¬ї –±—Г–і—Г—В –њ–Њ–ї—Г—З–µ–љ—Л —В—А–Є–≥—А–∞–Љ–Љ—Л ¬Ђ–Ї—Г–њ¬ї, ¬Ђ—Г–њ–Є¬ї, ¬Ђ–њ–Є—В¬ї –Є —В.–і.
–Я–Њ–Ї—А—Л—В–Є–µ –Њ–і–љ–Њ–≥–Њ –Ј–∞–њ—А–Њ—Б–∞ —А–∞—Б—Б—З–Є—В—Л–≤–∞–ї–Њ—Б—М —Б–ї–µ–і—Г—О—Й–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ:
–Ю–њ—А–µ–і–µ–ї—П–µ–Љ —В—А–Є–≥—А–∞–Љ–Љ—Л –і–ї—П –Ј–∞–њ—А–Њ—Б–∞ вАФ 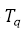
–Ю–њ—А–µ–і–µ–ї—П–µ–Љ —В—А–Є–≥—А–∞–Љ–Љ—Л –і–ї—П –Ї–∞–љ–і–Є–і–∞—В–∞ вАФ 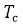
–Ю–њ—А–µ–і–µ–ї—П–µ–Љ —В—А–Є–≥—А–∞–Љ–Љ—Л –Ј–∞–њ—А–Њ—Б–∞, –Ї–Њ—В–Њ—А—Л–µ –µ—Б—В—М —В–∞–Ї–ґ–µ –≤ —В—А–Є–≥—А–∞–Љ–Љ–∞—Е –Ї–∞–љ–і–Є–і–∞—В–∞: 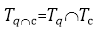
–Я–Њ–Ї—А—Л—В–Є–µ –Њ–њ—А–µ–і–µ–ї—П–µ–Љ, –Ї–∞–Ї –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —В—А–Є–≥—А–∞–Љ–Љ –Ј–∞–њ—А–Њ—Б–∞, –Ї–Њ—В–Њ—А—Л–µ –µ—Б—В—М —В–∞–Ї–ґ–µ –≤ —В—А–Є–≥—А–∞–Љ–Љ–∞—Е –Ї–∞–љ–і–Є–і–∞—В–∞ –Ї –Ї–Њ–ї–Є—З–µ—Б—В–≤—Г —В—А–Є–≥—А–∞–Љ–Љ –Ј–∞–њ—А–Њ—Б–∞:
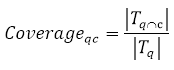
–Ф–ї—П –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—П –њ–Њ–Ї—А—Л—В–Є—П –Ї–∞–љ–і–Є–і–∞—В–Њ–Љ –≤—Б–µ—Е –Ј–∞–њ—А–Њ—Б–Њ–≤ –љ–∞ —Б—В—А–∞–љ–Є—Ж–µ –±–µ—А–µ—В—Б—П —Б—А–µ–і–љ–µ–µ –Ј–љ–∞—З–µ–љ–Є–µ –њ–Њ–Ї—А—Л—В–Є–є:
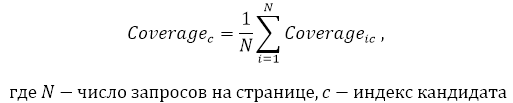
–Т –Ї–∞—З–µ—Б—В–≤–µ –і—А—Г–≥–Њ–≥–Њ —А–µ—И–µ–љ–Є—П —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞–ї–∞—Б—М –љ–Њ—А–Љ–∞–ї–Є–Ј–∞—Ж–Є—П –Ј–∞–њ—А–Њ—Б–Њ–≤ –Є –Ї–∞–љ–і–Є–і–∞—В–Њ–≤, –∞ –Ј–∞—В–µ–Љ —А–∞—Б—З–µ—В tf-idf –Љ–µ–ґ–і—Г –Ј–∞–њ—А–Њ—Б–Њ–Љ –Є –Ї–∞–љ–і–Є–і–∞—В–Њ–Љ. –Ґ—А–Є–≥—А–∞–Љ–Љ—Л –±—Л–ї–Є –≤—Л–±—А–∞–љ—Л, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Њ–љ–Є –њ–Њ–Ј–≤–Њ–ї—П—О—В —З–∞—Б—В–Є—З–љ–Њ —Г—З–Є—В—Л–≤–∞—В—М –Њ–і–љ–Њ–Ї–Њ—А–µ–љ–љ—Л–µ —Б–ї–Њ–≤–∞. –Э–∞–њ—А–Є–Љ–µ—А, ¬Ђ–і–ї—П –і–Њ–Љ–∞¬ї –Є ¬Ђ–і–Њ–Љ–∞—И–љ–Є–є¬ї –і–∞–і—Г—В –љ–µ–љ—Г–ї–µ–≤–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –њ—А–Є –њ–Њ–Ї—А—Л—В–Є–Є —В—А–Є–≥—А–∞–Љ–Љ–∞–Љ–Є, –∞ –њ—А–Є —А–∞—Б—З–µ—В–µ tf-idf –±—Л–ї –±—Л 0.
–Ъ–∞–љ–і–Є–і–∞—В —Б –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ—Л–Љ –њ–Њ–Ї—А—Л—В–Є–µ–Љ –≤—Л–±–Є—А–∞–µ—В—Б—П –і–ї—П —Н—В–Њ–є —Б—В—А–∞–љ–Є—Ж—Л, –њ–Њ—Б–ї–µ —З–µ–≥–Њ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В —А–∞—Б—И–Є—А–µ–љ–Є–µ –µ–≥–Њ –љ–∞–Ј–≤–∞–љ–Є–µ–Љ –Ї–Њ–Љ–њ–∞–љ–Є–Є –Є–ї–Є –Љ–∞–≥–∞–Ј–Є–љ–∞, –Ї–Њ—В–Њ—А–Њ–µ –±—Л–ї–Њ –њ–Њ–ї—Г—З–µ–љ–Њ —А–∞–љ–µ–µ.
–Я—А–Є–Љ–µ—А—Л —Б–≥–µ–љ–µ—А–Є—А–Њ–≤–∞–љ–љ—Л—Е —В–∞–є—В–ї–Њ–≤:
| –Ч–∞–њ—А–Њ—Б—Л | Title |
| –Љ–µ–±–µ–ї—М –і–ї—П —В–µ–ї–µ–≤–Є–Ј–Њ—А–∞ –Љ–µ–±–µ–ї—М –њ–Њ–і —В–µ–ї–µ–≤–Є–Ј–Њ—А –Љ–µ–±–µ–ї—М –і–ї—П —В–≤ | –Ь–µ–±–µ–ї—М –њ–Њ–і —В–µ–ї–µ–≤–Є–Ј–Њ—А –≤ —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–Љ —Б—В–Є–ї–µ –Њ—В –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–Ґ—Г–Љ–±–∞–Ф–Њ–Љ¬ї |
| –ї–µ—В–љ–Є–є –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ—Л–є –Њ—В–і—Л—Е –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ—Л–є –Њ—В–і—Л—Е –љ–∞ –њ—А–Є—А–Њ–і–µ –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ—Л–є –Њ—В–і—Л—Е –∞–Ї—В–Є–≤–љ—Л–є –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ—Л–є –Њ—В–і—Л—Е –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є—П –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ–Њ–≥–Њ –Њ—В–і—Л—Е–∞ | –Ю—А–≥–∞–љ–Є–Ј–∞—Ж–Є—П –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ–Њ–≥–Њ –≤—Л–µ–Ј–і–∞ –љ–∞ –њ—А–Є—А–Њ–і—Г | –Ъ–Њ—А–њ–Ъ–ї–∞–± |
| –±–∞—Б—Б–µ–є–љ –і–µ—В—Б–Ї–Є–є –і–ї—П –і–∞—З–Є –±–∞—Б—Б–µ–є–љ –і–µ—В—Б–Ї–Є–є –Ї—Г–њ–Є—В—М –±–∞—Б—Б–µ–є–љ –і–ї—П –і–µ—В–µ–є –Ї—Г–њ–Є—В—М –і–µ—В—Б–Ї–Є–µ –±–∞—Б—Б–µ–є–љ—Л –і–ї—П –Љ–∞–ї—Л—И–µ–є –і–µ—В—Б–Ї–Є–є –±–∞—Б—Б–µ–є–љ –Ї—Г–њ–Є—В—М –≤ –Љ–Њ—Б–Ї–≤–µ | –Ф–µ—В—Б–Ї–Є–µ –±–∞—Б—Б–µ–є–љ—Л –≤ –Ь–Њ—Б–Ї–≤–µ вАФ –Ї—Г–њ–Є—В—М –±–∞—Б—Б–µ–є–љ –і–ї—П –і–µ—В–µ–є –Њ—В –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–Р–Ї–≤–∞–њ–Њ–ї–Є—Б¬ї |
–У–µ–љ–µ—А–∞—Ж–Є—П Description
–У–µ–љ–µ—А–∞—Ж–Є—П description –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В—Б—П –≥–Њ—А–∞–Ј–і–Њ –±–Њ–ї–µ–µ —Б–ї–Њ–ґ–љ–Њ–є –Ј–∞–і–∞—З–µ–є, —В–∞–Ї –Ї–∞–Ї –≤ description –Њ–±—Л—З–љ–Њ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В –і–ї–Є–љ–љ—Л–µ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П, –Ї–Њ—В–Њ—А—Л–µ –і–Њ–ї–ґ–љ—Л –±—Л—В—М —Б–Њ–≥–ї–∞—Б–Њ–≤–∞–љ—Л –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є. –Ф–∞–ґ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –љ–µ–є—А–Њ–љ–љ—Л—Е —Б–µ—В–µ–є –і–ї—П –≥–µ–љ–µ—А–∞—Ж–Є–Є —В–µ–Ї—Б—В–Њ–≤ –љ–µ –Љ–Њ–ґ–µ—В –і–∞—В—М –њ—А–Є–µ–Љ–ї–µ–Љ—Л–є —Г—А–Њ–≤–µ–љ—М —В–µ–Ї—Б—В–Њ–≤ –і–ї—П —А—Г—Б—Б–Ї–Њ–≥–Њ —П–Ј—Л–Ї–∞. –Я–Њ—Н—В–Њ–Љ—Г –Є–і–µ—П –њ–Є—Б–∞—В—М —В–µ–Ї—Б—В—Л —Б –љ—Г–ї—П –±—Л–ї–∞ –Њ—В–Ї–ї–Њ–љ–µ–љ–∞ –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є —Б —Б–∞–Љ–Њ–≥–Њ –љ–∞—З–∞–ї–∞.
–Х—Б–ї–Є —В–µ–Ї—Б—В –љ–µ –њ–Њ–ї—Г—З–∞–µ—В—Б—П —Б–≥–µ–љ–µ—А–Є—А–Њ–≤–∞—В—М, –Ј–љ–∞—З–Є—В –љ—Г–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –≥–Њ—В–Њ–≤—Л–є. –Э–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —В–µ–Ї—Б—В —Б —З—Г–ґ–Є—Е —Б—В—А–∞–љ–Є—Ж –љ–µ–ї—М–Ј—П, —В–∞–Ї –Ї–∞–Ї —Г –љ–∞—Б —Б–≤–Њ–Є –Ї–Њ–љ–Ї—Г—А–µ–љ—В–љ—Л–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞ –Є –і–µ–є—Б—В–≤–Є—В–µ–ї—М–љ–Њ —А–µ–ї–µ–≤–∞–љ—В–љ—Л–Љ –±—Г–і–µ—В —В–µ–Ї—Б—В —В–Њ–ї—М–Ї–Њ —Б –љ–∞—И–µ–≥–Њ —Б–∞–є—В–∞. –Я–Њ—Н—В–Њ–Љ—Г –Ј–∞–і–∞—З–∞ –≥–µ–љ–µ—А–∞—Ж–Є–Є description –њ—А–µ–≤—А–∞—Й–∞–µ—В—Б—П –≤ –Ј–∞–і–∞—З—Г –њ–Њ–Є—Б–Ї–∞ –њ–Њ–і—Е–Њ–і—П—Й–µ–≥–Њ —В–µ–Ї—Б—В–∞ –љ–∞ –љ–∞—И–µ–Љ —Б–∞–є—В–µ. –Ф–ї—П —В–Њ–≥–Њ, —З—В–Њ–±—Л –љ–µ –њ—А–Є–і—Г–Љ—Л–≤–∞—В—М –Њ–≥—А–Њ–Љ–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ—А–∞–≤–Є–ї, —А–µ—И–Є–ї–Є –Њ–±—Г—З–Є—В—М –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А, –Ї–Њ—В–Њ—А—Л–є –±—Г–і–µ—В –њ—А–Є–љ–Є–Љ–∞—В—М –љ–∞ –≤—Е–Њ–і –љ–µ–Ї–Њ—В–Њ—А—Л–є —В–µ–Ї—Б—В –Є –Њ–њ—А–µ–і–µ–ї—П—В—М, —П–≤–ї—П–µ—В—Б—П –ї–Є —Н—В–Њ—В —В–µ–Ї—Б—В —З–∞—Б—В—М—О description –Є–ї–Є –љ–µ—В.
–Ф–ї—П –Њ–±—Г—З–µ–љ–Є—П –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –±–Њ–ї—М—И–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –і–∞–љ–љ—Л—Е. –Ф–ї—П —Н—В–Њ–≥–Њ, –∞–љ–∞–ї–Њ–≥–Є—З–љ–Њ title, –≤—Л–Ї–∞—З–∞–ї–Є —Б—В—А–∞–љ–Є—Ж—Л –Є–Ј –≤—Л–і–∞—З–Є –њ–Њ –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Є–Љ –Ј–∞–њ—А–Њ—Б–∞–Љ. –Т –Ї–∞—З–µ—Б—В–≤–µ –њ–Њ–ї–Њ–ґ–Є—В–µ–ї—М–љ—Л—Е –њ—А–Є–Љ–µ—А–Њ–≤ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Є—Б—М —Д–∞–Ї—В–Є—З–µ—Б–Ї–Є–µ description, —А–∞–Ј–±–Є—В—Л–µ –љ–∞ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П. –Т –Ї–∞—З–µ—Б—В–≤–µ –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ—Л—Е –њ—А–Є–Љ–µ—А–Њ–≤ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Є—Б—М –Њ—Б—В–∞–ї—М–љ—Л–µ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –љ–∞ —Б—В—А–∞–љ–Є—Ж–µ.
–Т—Б–µ –њ–Њ–ї—Г—З–µ–љ–љ—Л–µ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –њ—А–µ–і—Б—В–∞–≤–ї—П—О—В —Б–Њ–±–Њ–є –Ї–Њ—А–њ—Г—Б, –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –≤ —Н—В–Њ–Љ –Ї–Њ—А–њ—Г—Б–µ –њ—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ–Њ –љ–Њ—А–Љ–∞–ї–Є–Ј–Њ–≤–∞–ї–Є.
–Ф–ї—П –Њ–±—Г—З–µ–љ–Є—П –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –њ—А–µ–і—Б—В–∞–≤–Є—В—М –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –≤ –≤–Є–і–µ –≤–µ–Ї—В–Њ—А–∞ —З–Є—Б–ї–µ. –•–Њ—А–Њ—И–Њ –Ј–∞—А–µ–Ї–Њ–Љ–µ–љ–і–Њ–≤–∞–≤—И–Є–є —Б–µ–±—П –Љ–µ—В–Њ–і —Н—В–Њ TF-IDF. –С–Є–±–ї–Є–Њ—В–µ–Ї–∞ sklearn –њ—А–µ–і–Њ—Б—В–∞–≤–ї—П–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М —В–∞–Ї–Њ–≥–Њ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П —Б –њ–Њ–Љ–Њ—Й—М—О –Љ–µ—В–Њ–і–∞ TfidfVectorizer. –Т —Н—В–Њ–Љ –Љ–µ—В–Њ–і–µ –Љ–Њ–ґ–љ–Њ —Г–Ї–∞–Ј–∞—В—М –Љ–Є–љ–Є–Љ–∞–ї—М–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ–Њ–≤—В–Њ—А–µ–љ–Є—П —В–µ—А–Љ–∞, –љ–Є–ґ–µ –Ї–Њ—В–Њ—А–Њ–≥–Њ —В–µ—А–Љ –љ–µ –±—Г–і–µ—В –≤–Ї–ї—О—З–µ–љ –≤ —Б–ї–Њ–≤–∞—А—М. –≠—В–Њ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –Њ—З–µ–љ—М –њ—А–Њ—Б—В–Њ —Г–і–∞–ї–Є—В—М —А–µ–і–Ї–Є–µ —Б–ї–Њ–≤–∞. –І–∞—Б—В–Њ —Н—В–Њ —Б–ї–Њ–≤–∞ —Б –Њ—А—Д–Њ–≥—А–∞—Д–Є—З–µ—Б–Ї–Є–Љ–Є –Њ—И–Є–±–Ї–∞–Љ–Є –Є–ї–Є —Б–њ–µ—Ж–Є—Д–Є—З–љ—Л–µ —В–µ—А–Љ–Є–љ—Л. –£–і–∞–ї–µ–љ–Є–µ —А–µ–і–Ї–Є—Е —Б–ї–Њ–≤ —Б—Г—Й–µ—Б—В–≤–µ–љ–љ–Њ —Б–Њ–Ї—А–∞—Й–∞–µ—В –Њ–±—К–µ–Љ —Б–ї–Њ–≤–∞—А—П –Є —Б–љ–Є–ґ–∞–µ—В –≤–µ—А–Њ—П—В–љ–Њ—Б—В—М –њ–µ—А–µ–Њ–±—Г—З–µ–љ–Є—П –Љ–Њ–і–µ–ї–Є –≤ –і–∞–ї—М–љ–µ–є—И–µ–Љ.
–≠—В–Њ—В –Љ–µ—В–Њ–і –њ–Њ–Ј–≤–Њ–ї—П–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –љ–µ —В–Њ–ї—М–Ї–Њ –Њ–і–Є–љ–Њ—З–љ—Л–µ —Б–ї–Њ–≤–∞, –љ–Њ –Є —Б–ї–Њ–≤–Њ—Б–Њ—З–µ—В–∞–љ–Є—П –Є–Ј –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е —Б–ї–Њ–≤. –Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–ї–Њ–≤ —П–≤–ї—П–µ—В—Б—П –≤—Е–Њ–і–љ—Л–Љ –њ–∞—А–∞–Љ–µ—В—А–Њ–Љ. –Ґ.–Ї. –Љ—Л –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А –љ–∞ –і–ї–Є–љ–љ—Л—Е —В–µ–Ї—Б—В–∞—Е, –≤ –Ї–Њ—В–Њ—А—Л—Е –Љ–љ–Њ–≥–Њ —Г—Б—В–Њ–є—З–Є–≤—Л—Е —Б–ї–Њ–≤–Њ—Б–Њ—З–µ—В–∞–љ–Є–є (–љ–Є–Ј–Ї–∞—П —Ж–µ–љ–∞, –±–Њ–ї—М—И–Њ–є –≤—Л–±–Њ—А –Є —В.–і.), –Є–љ—В—Г–Є—В–Є–≤–љ–Њ –њ–Њ–љ—П—В–љ–Њ, —З—В–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –±–Є–≥—А–∞–Љ–Љ (—Б–Њ—З–µ—В–∞–љ–Є–є –Є–Ј 2 —Б–ї–Њ–≤) –і–Њ–ї–ґ–љ–Њ –њ–Њ–≤—Л—Б–Є—В—М –Ї–∞—З–µ—Б—В–≤–Њ –Љ–Њ–і–µ–ї–Є.
–Ф–ї—П –Њ–±—Г—З–µ–љ–Є—П –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Є—Б—М –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –Љ–µ—В–Њ–і–Њ–≤: LogisticRegression, RandomForest, SGD.
–°–∞–Љ—Л–є –ї—Г—З—И–Є–є —А–µ–Ј—Г–ї—М—В–∞—В –њ–Њ–Ї–∞–Ј–∞–ї SGD (—Б—В–Њ—Е–∞—Б—В–Є—З–µ—Б–Ї–Є–є –≥—А–∞–і–Є–µ–љ—В–љ—Л–є —Б–њ—Г—Б–Ї).
–Т —А–µ–Ј—Г–ї—М—В–∞—В–µ –≤–∞–ї–Є–і–∞—Ж–Є–Є –љ–∞ –Њ—В–ї–Њ–ґ–µ–љ–љ–Њ–є –≤—Л–±–Њ—А–Ї–µ –Є–Ј 92 —В—Л—Б—П—З –±—Л–ї –њ–Њ–ї—Г—З–µ–љ —Б–ї–µ–і—Г—О—Й–Є–є —А–µ–Ј—Г–ї—М—В–∞—В:
–Ь–∞—В—А–Є—Ж–∞ –Њ—И–Є–±–Њ–Ї –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—Ж–Є–Є

–Ю—В—З–µ—В –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—Ж–Є–Є
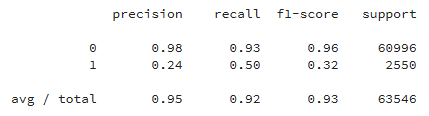
–Я–Њ —А–µ–Ј—Г–ї—М—В–∞—В–∞–Љ –≤–Є–і–љ–Њ, —З—В–Њ –Љ—Л –і–Њ–±–Є–ї–Є—Б—М —В–Њ—З–љ–Њ—Б—В–Є –≤ 79% –њ–Њ –њ–Њ–ї–Њ–ґ–Є—В–µ–ї—М–љ–Њ–Љ—Г –Ї–ї–∞—Б—Б—Г. –≠—В–Њ –Њ—З–µ–љ—М —Е–Њ—А–Њ—И–Є–є —А–µ–Ј—Г–ї—М—В–∞—В, –µ—Б–ї–Є –њ–Њ–љ–Є–Љ–∞—В—М, —З—В–Њ –њ—А–Є –Њ–±—Г—З–µ–љ–Є–Є, –Љ—Л –њ–Њ–Љ–µ—В–Є–ї–Є –≤—Б–µ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –љ–∞ —Б—В—А–∞–љ–Є—Ж–µ –Ї–∞–Ї –Њ—В—А–Є—Ж–∞—В–µ–ї—М–љ—Л–µ –њ—А–Є–Љ–µ—А—Л –Є –≥–∞—А–∞–љ—В–Є—А–Њ–≤–∞—В—М —З—В–Њ —Б—А–µ–і–Є –љ–Є—Е –і–µ–є—Б—В–≤–Є—В–µ–ї—М–љ–Њ –љ–µ—В –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–є –њ–Њ—Е–Њ–ґ–Є—Е –љ–∞ description –Љ—Л –љ–µ –Љ–Њ–≥–ї–Є.
–Я—А–Є–Љ–µ—А—Л –ї–Њ–ґ–љ–Њ–њ–Њ–ї–Њ–ґ–Є—В–µ–ї—М–љ—Л—Е –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–є:
¬Ј –£ –љ–∞—Б –±–Њ–ї—М—И–Њ–є –≤—Л–±–Њ—А –Љ–µ–і–Є—Ж–Є–љ—Б–Ї–Њ–≥–Њ –Њ–±–Њ—А—Г–і–Њ–≤–∞–љ–Є—П, —В–Њ–≤–∞—А—Л –Љ–Њ–ґ–љ–Њ –Ї—Г–њ–Є—В—М –љ–∞ –≤—Л–≥–Њ–і–љ—Л—Е —Г—Б–ї–Њ–≤–Є—П—Е.
¬Ј –У–∞—А–∞–љ—В–Є—П 5 –ї–µ—В!
¬Ј –Я—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞ –њ–Њ–Ї—Г–њ–Ї–Є –љ–∞ —Б–∞–є—В–µ d-lock.
¬Ј –Ф–ї—П –Ј–∞–њ–Є—Б–Є –љ–∞ –њ—А–Є–µ–Љ –Ї –Њ—А—В–Њ–і–Њ–љ—В—Г –і–µ—В—Б–Ї–Њ–є —Б—В–Њ–Љ–∞—В–Њ–ї–Њ–≥–Є–Є ¬Ђ–Ь–∞—А—В–Є–љ–Ї–∞¬ї, —Г—В–Њ—З–љ–µ–љ–Є—П –∞–Ї—В—Г–∞–ї—М–љ–Њ–є —Ж–µ–љ—Л —Г—Б—В–∞–љ–Њ–≤–Ї–Є –љ–µ–≤–Є–і–Є–Љ—Л—Е –±—А–µ–Ї–µ—В–Њ–≤ –Є —Б—В–Њ–Є–Љ–Њ—Б—В–Є –і—А—Г–≥–Є—Е —Г—Б–ї—Г–≥ –Ј–≤–Њ–љ–Є—В–µ –љ–∞—И–Є–Љ –Ї–Њ–љ—Б—Г–ї—М—В–∞–љ—В–∞–Љ –њ–Њ –љ–Њ–Љ–µ—А—Г, —Г–Ї–∞–Ј–∞–љ–љ–Њ–Љ—Г –≤ —А–∞–Ј–і–µ–ї–µ –Ъ–Њ–љ—В–∞–Ї—В—Л.
¬Ј –Т –Љ–∞–≥–∞–Ј–Є–љ–µ —Б—Г—Й–µ—Б—В–≤—Г–µ—В –љ–∞–Ї–Њ–њ–Є—В–µ–ї—М–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ —Б–Ї–Є–і–Њ–Ї –і–ї—П –њ–Њ—Б—В–Њ—П–љ–љ—Л—Е –Ї–ї–Є–µ–љ—В–Њ–≤.
¬Ј –Я–Њ –ї—Г—З—И–µ–є —Ж–µ–љ–µ –±—Л—Б—В—А–Њ –Є —Г–і–Њ–±–љ–Њ!
¬Ј –Я–Њ—Н—В–Њ–Љ—Г —А–∞—Б—Б–Љ–Њ—В—А–Є–Љ, –њ–Њ –Ї–∞–Ї–Є–Љ –њ–∞—А–∞–Љ–µ—В—А–∞–Љ –Њ—В–ї–Є—З–∞—О—В—Б—П –Љ–Њ–і–µ–ї–Є –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є.
¬Ј –Т—Л–±–Є—А–∞–є—В–µ –Є –Ј–∞–Ї–∞–Ј—Л–≤–∞–є—В–µ —Г –љ–∞—Б вАФ –і–µ—И–µ–≤–Њ, –±—Л—Б—В—А–Њ –Є —Б –љ–∞–і–µ–ґ–љ–Њ–є –і–Њ—Б—В–∞–≤–Ї–Њ–є.
–Я–Њ–ї–љ–Њ—В–∞ –њ–Њ–ї—Г—З–Є–ї–∞—Б—М –Њ—З–µ–љ—М –љ–Є–Ј–Ї–Њ–є, –љ–Њ –і–ї—П —А–∞–±–Њ—В—Л –∞–ї–≥–Њ—А–Є—В–Љ–∞ —Н—В–Њ –љ–µ –Ї—А–Є—В–Є—З–љ–Њ.
–Я–Њ—Б–ї–µ –Њ–±—Г—З–µ–љ–Є—П –Љ–Њ–і–µ–ї–Є, –Ї–Њ—В–Њ—А–∞—П —Б–Љ–Њ–ґ–µ—В –≤—Л–і–µ–ї—П—В—М –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П —Б –љ–∞—И–µ–є —Б—В—А–∞–љ–Є—Ж—Л, –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ —А–∞–Ј—А–∞–±–Њ—В–∞—В—М –∞–ї–≥–Њ—А–Є—В–Љ, –Ї–∞–Ї —Н—В–Є –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П —Б–Њ–µ–і–Є–љ—П—В—М –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є. –Я–Њ—Б–ї–µ –∞–љ–∞–ї–Є–Ј–∞ —Б—Г—Й–µ—Б—В–≤—Г—О—Й–Є—Е description –њ—А–Є—И–ї–Є –Ї –≤—Л–≤–Њ–і—Г, —З—В–Њ –±–Њ–ї—М—И–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ description —Д–Њ—А–Љ–Є—А—Г—О—В—Б—П –њ–Њ —И–∞–±–ї–Њ–љ—Г:
¬Ђ–Ю—Б–љ–Њ–≤–љ–∞—П —З–∞—Б—В—М¬ї + ¬Ђ–Я—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞¬ї
–Ю—Б–љ–Њ–≤–љ–∞—П —З–∞—Б—В—М вАФ —Н—В–Њ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–µ, –Ї–Њ—В–Њ—А–Њ–µ –Њ—В—А–∞–ґ–∞–µ—В, —З—В–Њ –Є–Љ–µ–љ–љ–Њ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М –Љ–Њ–ґ–µ—В –љ–∞–є—В–Є –љ–∞ —Н—В–Њ–є —Б—В—А–∞–љ–Є—Ж–µ.
¬Ј –Ф–µ—В—Б–Ї–∞—П –Њ—А—В–Њ–њ–µ–і–Є—З–µ—Б–Ї–∞—П –њ–Њ–і—Г—И–Ї–∞ TRELAX Optima Baby –Я03 —Б–Њ–Ј–і–∞–љ–∞ –і–ї—П –њ–Њ–ї–љ–Њ—Ж–µ–љ–љ–Њ–≥–Њ —Б–љ–∞ –Є –Њ—В–і—Л—Е–∞ –і–µ—В–µ–є –≤ –≤–Њ–Ј—А–∞—Б—В–µ –Њ—В —В—А–µ—Е –ї–µ—В.
¬Ј –Э–Њ–≤–Њ–≥–Њ–і–љ–Є–µ –њ–ї–∞—В—М—П –і–ї—П –і–µ–≤–Њ—З–µ–Ї, —Н—Д—Д–µ–Ї—В–љ—Л–µ –Є –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Л–µ, –Љ–Њ–ґ–љ–Њ –Ї—Г–њ–Є—В—М –≤ –Є–љ—В–µ—А–љ–µ—В-–Љ–∞–≥–∞–Ј–Є–љ–µ Evikris.
¬Ј –Т—Л—Б–Њ–Ї–Њ—Б–Ї–Њ—А–Њ—Б—В–љ–Њ–є –≤–Є–±—А–Њ–Љ–∞—Б—Б–∞–ґ–µ—А ERGO HAND вАФ —Г—Б—В—А–Њ–є—Б—В–≤–Њ –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Љ–∞—Б—Б–∞–ґ–∞ –≤ –і–Њ–Љ–∞—И–љ–Є—Е —Г—Б–ї–Њ–≤–Є—П—Е.
–Я—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞ вАФ —Н—В–Њ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –њ—А–Њ –≤—Л–≥–Њ–і—Г, –Ї–Њ—В–Њ—А—Г—О –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М –љ–∞–є–і–µ—В –љ–∞ —Б–∞–є—В–µ, —З–∞—Б—В–Њ —Н—В–Њ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –њ—А–Њ –і–Њ—Б—В–∞–≤–Ї—Г, –≥–∞—А–∞–љ—В–Є—О, –Ї–∞—З–µ—Б—В–≤–Њ, –≤—Л–≥–Њ–і–љ—Л–µ —Ж–µ–љ—Л –Є —В.–і.
¬Ј –¶–µ–љ–∞ –Њ—В 550 —В—Л—Б.—А—Г–±–ї–µ–є
¬Ј –Ы—Г—З—И–µ–µ –Ї–∞—З–µ—Б—В–≤–Њ –Є –њ—А–µ–Ї—А–∞—Б–љ—Л–є —Б–µ—А–≤–Є—Б
¬Ј –£–і–Њ–±–љ—Л–є –Ї–∞—В–∞–ї–Њ–≥, –∞ —В–∞–Ї–ґ–µ –±–µ—Б–њ–ї–∞—В–љ–∞—П —Г—Б–ї—Г–≥–∞ –і–Њ—Б—В–∞–≤–Ї–Є вАФ –љ–∞—И–Є –≥–ї–∞–≤–љ—Л–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞
–Ф–ї—П –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—П, –Ї –Ї–∞–Ї–Њ–Љ—Г –ґ–µ —В–Є–њ—Г –њ—А–Є–љ–∞–і–ї–µ–ґ–Є—В –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–µ, –∞ —В–∞–Ї–ґ–µ –і–ї—П –Є—Е –њ–Њ—Б–ї–µ–і—Г—О—Й–µ–≥–Њ —А–∞–љ–ґ–Є—А–Њ–≤–∞–љ–Є—П –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П TF-IDF. –Ф–ї—П —Н—В–Њ–≥–Њ —Б—З–Є—В–∞–µ–Љ TF-IDF –Љ–µ–ґ–і—Г –≤—Б–µ–Љ–Є –Ј–∞–њ—А–Њ—Б–∞–Љ–Є –Є –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–µ–Љ, —Г—Б—А–µ–і–љ—П–µ–Љ –µ–≥–Њ. –Х—Б–ї–Є TF-IDF –Љ–µ–љ—М—И–µ –љ–µ–Ї–Њ—В–Њ—А–Њ–≥–Њ –њ–Њ—А–Њ–≥–∞, —В–Њ –≥–Њ–≤–Њ—А–Є–Љ, —З—В–Њ —Н—В–Њ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П —В–Є–њ–∞ ¬Ђ–Я—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞¬ї, –Є–љ–∞—З–µ —Н—В–Њ ¬Ђ–Ю—Б–љ–Њ–≤–љ–∞—П —З–∞—Б—В—М¬ї –Є –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П —Н—В–Њ–≥–Њ —В–Є–њ–∞ –њ–Њ —Б—А–µ–і–љ–µ–Љ—Г –Ј–љ–∞—З–µ–љ–Є—О TF-IDF —А–∞–љ–ґ–Є—А—Г—О—В—Б—П –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є.
–Т –Ї–∞—З–µ—Б—В–≤–µ –њ–Њ—А–Њ–≥–∞ –і–ї—П –Љ–Є–љ–Є–Љ–∞–ї—М–љ–Њ–≥–Њ TF-IDF –±—Л–ї –≤—Л–±—А–∞–љ –љ–µ –љ–Њ–ї—М, —В.–Ї. –µ—Б—В—М —А—П–і –њ–Њ–њ—Г–ї—П—А–љ—Л—Е —Б–ї–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ —З–∞—Б—В–Њ –µ—Б—В—М –≤ –Ј–∞–њ—А–Њ—Б–∞—Е, –љ–Њ –њ—А–Є —Н—В–Њ–Љ —З–∞—Б—В–Њ –≤—Б—В—А–µ—З–∞—О—В—Б—П –Є –≤ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П—Е —В–Є–њ–∞ ¬Ђ–Я—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞¬ї. –≠—В–Њ –њ—А–µ–і–ї–Њ–≥–Є, —Б–ї–Њ–≤–∞ –Ї—Г–њ–Є—В—М, –Ј–∞–Ї–∞–Ј–∞—В—М, —Ж–µ–љ–∞ –Є —В.–і.
–Ф–∞–ї–µ–µ —Д–Њ—А–Љ–Є—А—Г–µ–Љ —Г–ґ–µ —Д–Є–љ–∞–ї—М–љ—Л–є description:
–°—А–µ–і–Є –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–є —В–Є–њ–∞ ¬Ђ–Ю—Б–љ–Њ–≤–љ–∞—П —З–∞—Б—В—М¬ї –≤—Л–±–Є—А–∞–µ–Љ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–µ —Б –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ—Л–Љ —Б—А–µ–і–љ–Є–Љ TF-IDF. –Х—Б–ї–Є –і–ї–Є–љ–∞ —Н—В–Њ–≥–Њ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –±–Њ–ї—М—И–µ, —З–µ–Љ –Љ–Є–љ–Є–Љ–∞–ї—М–љ–∞—П –і–ї–Є–љ–∞ description, —В–Њ –≤–Њ–Ј–≤—А–∞—Й–∞–µ–Љ —А–µ–Ј—Г–ї—М—В–∞—В. –Х—Б–ї–Є –љ–µ—В, —В–Њ —Б—А–µ–і–Є –Њ—Б—В–∞–≤—И–Є—Е—Б—П –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–є —В–Є–њ–∞ ¬Ђ–Ю—Б–љ–Њ–≤–љ–∞—П —З–∞—Б—В—М¬ї –њ—Л—В–∞–µ–Љ—Б—П –љ–∞–є—В–Є –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–µ, —Г –Ї–Њ—В–Њ—А–Њ–≥–Њ –љ–µ—В –њ–µ—А–µ—Б–µ—З–µ–љ–Є–є —Б —Г–ґ–µ –≤—Л–±—А–∞–љ–љ—Л–Љ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–µ–Љ, –њ–Њ –љ–Њ—А–Љ–∞–ї–Є–Ј–Њ–≤–∞–љ–љ—Л–Љ —Б–ї–Њ–≤–∞–Љ, –њ—А–Є —Н—В–Њ–Љ –Є–≥–љ–Њ—А–Є—А—Г—О—В—Б—П —Б–ї—Г–ґ–µ–±–љ—Л–µ —З–∞—Б—В–Є —А–µ—З–Є (–њ—А–µ–і–ї–Њ–≥–Є, —Б–Њ—О–Ј—Л).
–Х—Б–ї–Є —В–∞–Ї–Њ–µ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–µ —Г–і–∞–ї–Њ—Б—М –љ–∞–є—В–Є, —В–Њ –і–Њ–±–∞–≤–ї—П–µ–Љ –µ–≥–Њ –Ї –њ–µ—А–≤–Њ–Љ—Г –Є —Б–љ–Њ–≤–∞ –њ—А–Њ–≤–µ—А—П–µ–Љ, –і–Њ—Б—В–∞—В–Њ—З–љ–Њ –ї–Є –і–ї–Є–љ—Л.
–Х—Б–ї–Є –љ–µ —Г–і–∞–ї–Њ—Б—М, —В–Њ –∞–љ–∞–ї–Њ–≥–Є—З–љ—Л–Љ –Њ–±—А–∞–Ј–Њ–Љ –њ—Л—В–∞–µ–Љ—Б—П –љ–∞–±—А–∞—В—М –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П —В–Є–њ–∞ ¬Ђ–Я—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞¬ї. –Я—А–Є —Н—В–Њ –њ—А–Є –≤—Л–±–Њ—А–µ –Њ—З–µ—А–µ–і–љ–Њ–≥–Њ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –њ—А–Њ–≤–µ—А—П–µ–Љ, —З—В–Њ –љ–µ—В –њ–µ—А–µ—Б–µ–Ї–∞—О—Й–Є—Е—Б—П —Б–ї–Њ–≤ —Б–Њ —Б–ї–Њ–≤–∞–Љ–Є, –Ї–Њ—В–Њ—А—Л–µ —Г–ґ–µ —В–Њ—З–љ–Њ –±—Г–і—Г—В –≤ —Д–Є–љ–∞–ї—М–љ–Њ–Љ description. –°–і–µ–ї–∞–љ–Њ —Н—В–Њ –і–ї—П —В–Њ–≥–Њ, —З—В–Њ–±—Л —А–µ–Ј—Г–ї—М—В–Є—А—Г—О—Й–Є–є description –≤—Л–≥–ї—П–і–µ–ї –µ—Б—В–µ—Б—В–≤–µ–љ–љ–Њ –Є –љ–µ —Б–Њ–і–µ—А–ґ–∞–ї –њ–µ—А–µ—Б–њ–∞–Љ–∞. –Ґ–∞–Ї–ґ–µ –µ—Б—В—М –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–µ –љ–∞ –і–Њ–±–∞–≤–ї–µ–љ–Є–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –µ—Б–ї–Є –Є—Е –±–Њ–ї—М—И–µ 3, —В–Њ description –≤—Л–≥–ї—П–і–Є—В, –Ї–∞–Ї –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –љ–µ—Б–≤—П–Ј–љ—Л—Е –Љ–µ–ґ–і—Г —Б–Њ–±–Њ–є –Ї–Њ—А–Њ—В–Ї–Є—Е –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є–є. –Т —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –Є –≤ –љ–µ–Ї–Њ—В–Њ—А—Л—Е –і—А—Г–≥–Є—Е —Б–ї—Г—З–∞—П—Е (–љ–∞–њ—А–Є–Љ–µ—А, –љ–∞ —Б—В—А–∞–љ–Є—Ж–µ –љ–µ—В —В–µ–Ї—Б—В–∞, –Ї–Њ—В–Њ—А—Л–є –Љ—Л –Љ–Њ–ґ–µ–Љ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Є –њ–Њ—Н—В–Њ–Љ—Г –љ–∞–Љ –љ–µ —Г–і–∞–ї–Њ—Б—М –њ–Њ–і–Њ–±—А–∞—В—М description), —Н—В—Г —А–∞–±–Њ—В—Л –њ—А–Є–і–µ—В—Б—П –≤—Л–њ–Њ–ї–љ–Є—В—М —Б–њ–µ—Ж–Є–∞–ї–Є—Б—В—Г.
–Я—А–Є–Љ–µ—А—Л —Б–≥–µ–љ–µ—А–Є—А–Њ–≤–∞–љ–љ—Л—Е description:
| –Ч–∞–њ—А–Њ—Б—Л | Description |
| —Б–ї—Г–ґ–±–∞ —Г–љ–Є—З—В–Њ–ґ–µ–љ–Є—П –Ї–ї–Њ–њ–Њ–≤ –≤ –Ї–≤–∞—А—В–Є—А–µ –Љ–Њ—Б–Ї–≤–∞—Б–ї—Г–ґ–±–∞ —Г–љ–Є—З—В–Њ–ґ–µ–љ–Є—П –Ї–ї–Њ–њ–Њ–≤ –≤ –Ї–≤–∞—А—В–Є—А–µ —Ж–µ–љ–∞—Г–љ–Є—З—В–Њ–ґ–µ–љ–Є–µ –Ї–ї–Њ–њ–Њ–≤—Г–љ–Є—З—В–Њ–ґ–µ–љ–Є–µ –Ї–ї–Њ–њ–Њ–≤ –≤ –Ї–≤–∞—А—В–Є—А–µ—Г–љ–Є—З—В–Њ–ґ–µ–љ–Є–µ –Ї–ї–Њ–њ–Њ–≤ –≤ –Ї–≤–∞—А—В–Є—А–µ –Љ–Њ—Б–Ї–≤–∞—Г–љ–Є—З—В–Њ–ґ–µ–љ–Є–µ –Ї–ї–Њ–њ–Њ–≤ –≤ –Ї–≤–∞—А—В–Є—А–µ —Ж–µ–љ–∞ | –Я–Њ–ї—Г—З–Є—В—М –њ–Њ–і—А–Њ–±–љ—Г—О –Ї–Њ–љ—Б—Г–ї—М—В–∞—Ж–Є—О, –∞ —В–∞–Ї–ґ–µ –Ј–∞–Ї–∞–Ј–∞—В—М –≤—Л–µ–Ј–і —Б–ї—Г–ґ–±—Л –њ–Њ —Г–љ–Є—З—В–Њ–ґ–µ–љ–Є—О –Ї–ї–Њ–њ–Њ–≤ –≤ –Ї–≤–∞—А—В–Є—А–∞—Е –Ь–Њ—Б–Ї–≤—Л –Є–ї–Є –Њ–±–ї–∞—Б—В–Є –Є –Њ–±—А–∞–±–Њ—В–Ї—Г –Ї–≤–∞—А—В–Є—А—Л –Љ–µ—В–Њ–і–Њ–Љ —Е–Њ–ї–Њ–і–љ–Њ–≥–Њ –Є–ї–Є –≥–Њ—А—П—З–µ–≥–Њ —В—Г–Љ–∞–љ–∞ –њ–Њ –і–Њ—Б—В—Г–њ–љ–Њ–є —Б—В–Њ–Є–Љ–Њ—Б—В–Є –Љ–Њ–ґ–љ–Њ –њ–Њ —В–µ–ї–µ—Д–Њ–љ–∞–Љ: 7 495 975-70-69, 8 800 200-36-77. |
| –≤—Л–њ–µ—З–Ї–∞ –Њ–њ—В–Њ–Љ –Њ—В –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П–≤—Л–њ–µ—З–Ї–∞ –Њ–њ—В–Њ–Љ –Њ—В –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П –≤ –Љ–Њ—Б–Ї–≤–µ–Ї–Њ–љ–і–Є—В–µ—А—Б–Ї–∞—П —Д–∞–±—А–Є–Ї–∞ –≤ –Љ–Њ—Б–Ї–≤–µ–њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М –≤—Л–њ–µ—З–Ї–Є–њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М –≤—Л–њ–µ—З–Ї–Є –≤ –Љ–Њ—Б–Ї–≤–µ—Д–∞–±—А–Є–Ї–∞ –Ї–Њ–љ–і–Є—В–µ—А—Б–Ї–Є—Е –Є–Ј–і–µ–ї–Є–є—Д–∞–±—А–Є–Ї–∞ –Ї–Њ–љ–і–Є—В–µ—А—Б–Ї–Є—Е –Є–Ј–і–µ–ї–Є–є –Љ–Њ—Б–Ї–≤–∞ | –Э–∞—И–∞ —Д–∞–±—А–Є–Ї–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В –±–Њ–ї–µ–µ 250 –љ–∞–Є–Љ–µ–љ–Њ–≤–∞–љ–Є–є –≤—Л–њ–µ—З–Ї–Є –Є –Ї–Њ–љ–і–Є—В–µ—А—Б–Ї–Є—Е –Є–Ј–і–µ–ї–Є–є –њ–Њ –Њ—А–Є–≥–Є–љ–∞–ї—М–љ—Л–Љ —А–µ—Ж–µ–њ—В–∞–Љ. –Ь—Л –њ—А–µ–і–ї–∞–≥–∞–µ–Љ –Ї–ї–Є–µ–љ—В–∞–Љ –Њ–≥—А–Њ–Љ–љ—Л–є –≤—Л–±–Њ—А –Є –≤—Л–≥–Њ–і–љ—Л–µ —Ж–µ–љ—Л. |
| –Љ–Њ–є–Ї–∞ –Њ–Ї–Њ–љ –С–µ—Б–Ї—Г–і–љ–Є–Ї–Њ–≤—Б–Ї–Є–є–Љ–Њ–є–Ї–∞ –Њ–Ї–Њ–љ –С–Є–±–Є—А–µ–≤–Њ–Љ–Њ–є–Ї–∞ –Њ–Ї–Њ–љ –С–Є—А—О–ї—С–≤–Њ –Т–Њ—Б—В–Њ—З–љ–Њ–µ–Љ–Њ–є–Ї–∞ –Њ–Ї–Њ–љ –С–Є—А—О–ї—С–≤–Њ –Ч–∞–њ–∞–і–љ–Њ–µ–Љ–Њ–є–Ї–∞ –Њ–Ї–Њ–љ –С–Њ–≥–Њ—А–Њ–і—Б–Ї–Њ–µ | –Ь—Л –Њ–Ї–∞–Ј—Л–≤–∞–µ–Љ —Г—Б–ї—Г–≥–Є –њ–Њ –Ь–Њ–є–Ї–µ –Њ–Ї–Њ–љ –≤ –С–Њ–≥–Њ—А–Њ–і—Б–Ї–Њ–Љ –Є –і—А—Г–≥–Є—Е —А–∞–є–Њ–љ–∞—Е –Ь–Њ—Б–Ї–≤—Л. –Ф–Њ—Б—В—Г–њ–љ—Л–µ —Ж–µ–љ—Л, –Т—Л—Б–Њ–Ї–Њ–µ –Ї–∞—З–µ—Б—В–≤–Њ, –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–µ –Є—Б–њ–Њ–ї–љ–µ–љ–Є–µ вАУ –≤–Њ—В –Њ—Б–љ–Њ–≤–љ—Л–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞ —Б–Њ—В—А—Г–і–љ–Є—З–µ—Б—В–≤–∞ —Б –Ї–Њ–Љ–њ–∞–љ–Є–µ–є ¬Ђ–Ъ–ї–Є–љ—В–∞¬ї. |
–°–µ–є—З–∞—Б –∞–ї–≥–Њ—А–Є—В–Љ –≥–µ–љ–µ—А–∞—Ж–Є–Є –Љ–µ—В–∞—В–µ–≥–Њ–≤ –Є–Љ–µ–µ—В —Б–µ—А—М–µ–Ј–љ—Л–є –љ–µ–і–Њ—Б—В–∞—В–Њ–Ї: –≤ –Њ–±–Њ–Є—Е —Б–ї—Г—З–∞—П—Е –љ–∞–Љ –љ—Г–ґ–µ–љ –Ї–Њ–љ—В–µ–љ—В —Б—В—А–∞–љ–Є—Ж—Л, –∞ –і–ї—П description –љ—Г–ґ–љ–Њ –µ—Й–µ –Є –љ–∞–ї–Є—З–Є–µ –њ–Њ–і—Е–Њ–і—П—Й–µ–≥–Њ —В–µ–Ї—Б—В–∞ –љ–∞ —Н—В–Њ–є —Б—В—А–∞–љ–Є—Ж–µ. –Х—Б–ї–Є –≤ —А–∞–±–Њ—В—Г –±–µ—А–µ—В—Б—П –њ—А–Њ–µ–Ї—В, –і–ї—П –Ї–Њ—В–Њ—А–Њ–≥–Њ —В—А–µ–±—Г–µ—В—Б—П —Б–Њ–Ј–і–∞—В—М –љ–Њ–≤—Л–µ —Б—В—А–∞–љ–Є—Ж—Л, —В–Њ —Н—В–Є –∞–ї–≥–Њ—А–Є—В–Љ—Л –љ–µ –±—Г–і—Г—В —А–∞–±–Њ—В–∞—В—М. –Ф–∞–ї—М–љ–µ–є—И–Є–µ —Г–ї—Г—З—И–µ–љ–Є—П –±—Г–і—Г—В –љ–∞–њ—А–∞–≤–ї–µ–љ—Л –љ–∞ —В–Њ, —З—В–Њ–±—Л –і–Њ–≤–µ—Б—В–Є –њ—А–Њ—Ж–µ–љ—В –∞–≤—В–Њ–Љ–∞—В–Є—З–µ—Б–Ї–Є –≥–µ–љ–µ—А–Є—А—Г–µ–Љ—Л—Е description –Є title –і–Њ 100%.






